


Diagnostic medical errors are a huge problem. Will A.I. come to the rescue?
A new study estimates ~800,000 Americans are permanently disabled or die each year from diagnostic medical errors. Concurrently, multiple reports look at ways this may be reduced, including artificial intelligence. In this edition of Ground Truths, I’ll review the scope of the problem and prospects for improvement that are desperately needed.
The New Report and Other Estimates
Billed as “the first national estimate of permanent morbidity and mortality resulting from diagnostic errors across all clinical settings”, Johns Hopkins researchers estimated the serious harms in the USA to be 795,000 (plausible range 598,000 to 1,023,000) per year, about three-fourths emanating from the “Big Three’ categories as seen below. That breaks down to over 370,000 deaths and 424,000 permanently disabled Americans, representing the most common cause of death or disability due to medical malpractice. The lead author, David Newman-Toker, said: “We focused here on the serious harms, but the number of diagnostic errors that happen out there in the U.S. each year is probably somewhere on the order of magnitude of 50 to 100 million.” The new number of annual deaths attributed to medical errors is higher than a previous Johns Hopkins report by Marty Makary and colleagues of ~250,000 deaths per year and their assertion that this is the 3rd leading cause of death, a proclamation that has been questioned by many as to its veracity. But the current report supports an even higher number of deaths that would come in third or fourth after heart disease and cancer.
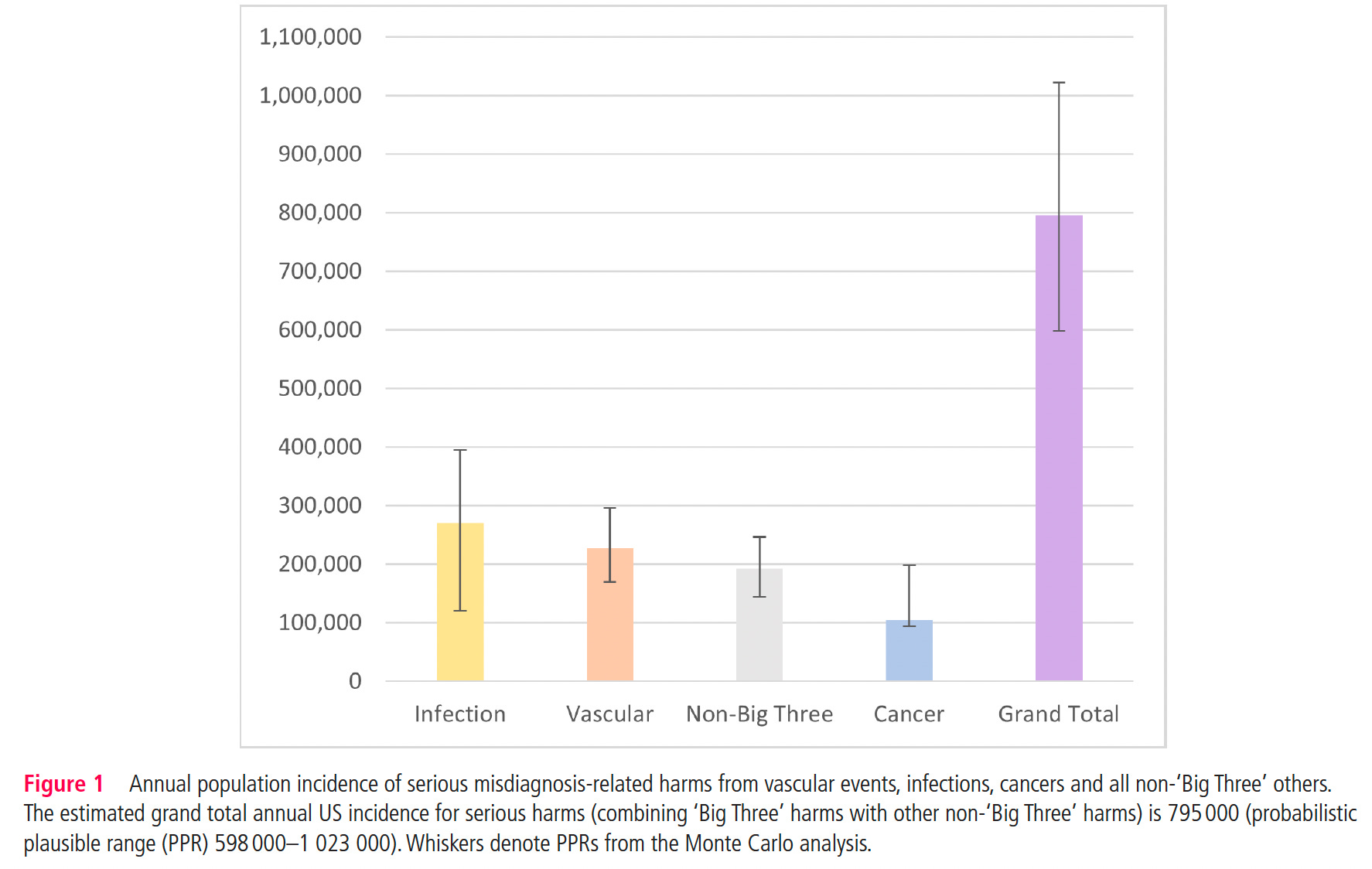
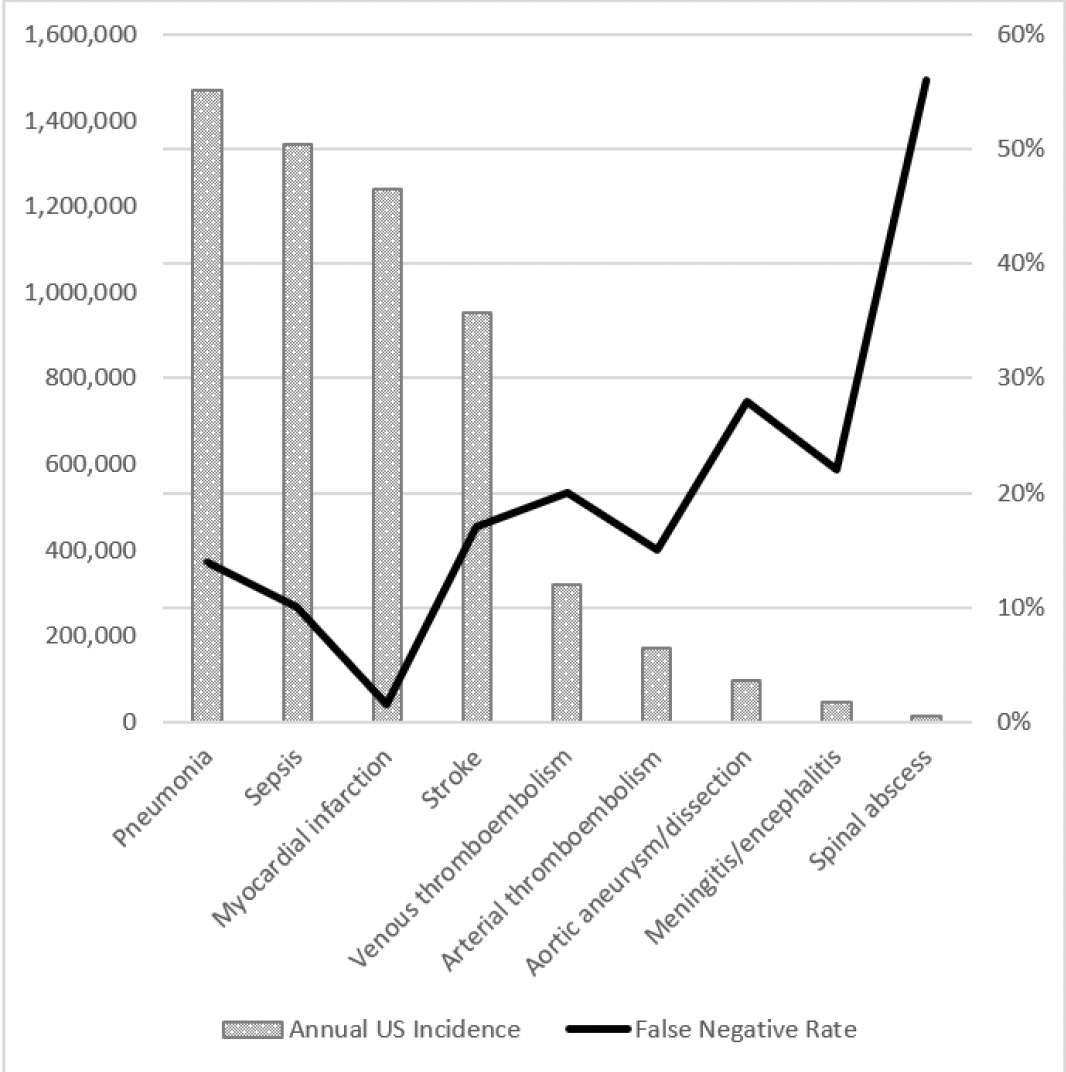
It’s hard to get precise numbers on the harm of medical diagnostic errors, so this work always relies on estimates based on relatively small samples and extrapolating to the large population. Nevertheless, these errors in diagnosis are undeniably highly prevalent and remain a very serious issue. In contrast to the new report that cut across out-patient clinic visits, emergency departments, and hospitals, Singh and colleagues from Baylor College of Medicine estimated the rate in the United States per year for out-patient diagnostic errors was 5%, or approximately 12 million. For emergency department (E.D.) errors, a recent Agency for Healthcare Research and Quality (AHRQ) 744-page report presented data to support a 5.7% diagnostic error rate and 0.3% of serious adverse event rate, translating to 1 of 350 suffering permanent disability or death, or 370,000 people, as extrapolated from the 130 million E.D. visit per year in the U.S. The report was criticized owing to much of the sources of data for extrapolation coming from countries outside the U.S., but it isn’t clear that would lead to overestimation. The high miss (false negative) rate for many diagnoses in the AHRQ report is seen in the Figure below.
The National Academy of Medicine concluded that most Americans will experience at least one diagnostic error in their lifetime. At autopsy, doctors who were “completely certain” of the cause of death were wrong 40% of the time. So anywhere you try to get a handle on the magnitude of the problem, it’s big. Of course, you won’t likely get the right treatment if you have the wrong diagnosis, so this critical decision has major downstream impact. When combined, “recent studies have found that 10-15% of all clinical decisions regarding diagnosis and treatment are inaccurate.”
A New Randomized Trial: Collective Human Intelligence
This week, Damon Centola and colleagues published a very interesting randomized trial of medical diagnostic accuracy in nearly 3,000 physicians; about 85% were primary care clinicians. Seven diagnostic vignettes were presented online via a study app. The control group (N=888) worked on their own, whereas the network group (N=2,053) were provided data from the diagnostic estimates of the other clinicians.

Here’s an example for one of the vignettes used in the trial. Each were selected because of their known high rates of error (such as acute heart event, low back pain, geriatric care).

The main results are shown below in the 2 graphs, at left, for improvement of risk assessment and, at right, for providing the correct recommendation. We knew long before this study the plain, statistical fact: 50% of doctors are below average in performance. The researchers broke the clinicians into quartiles for accuracy and you can see the least accurate group benefited greatly from the network sharing, the intervention that was tested. There was no improvement or reduction in accuracy among the best clinicians.
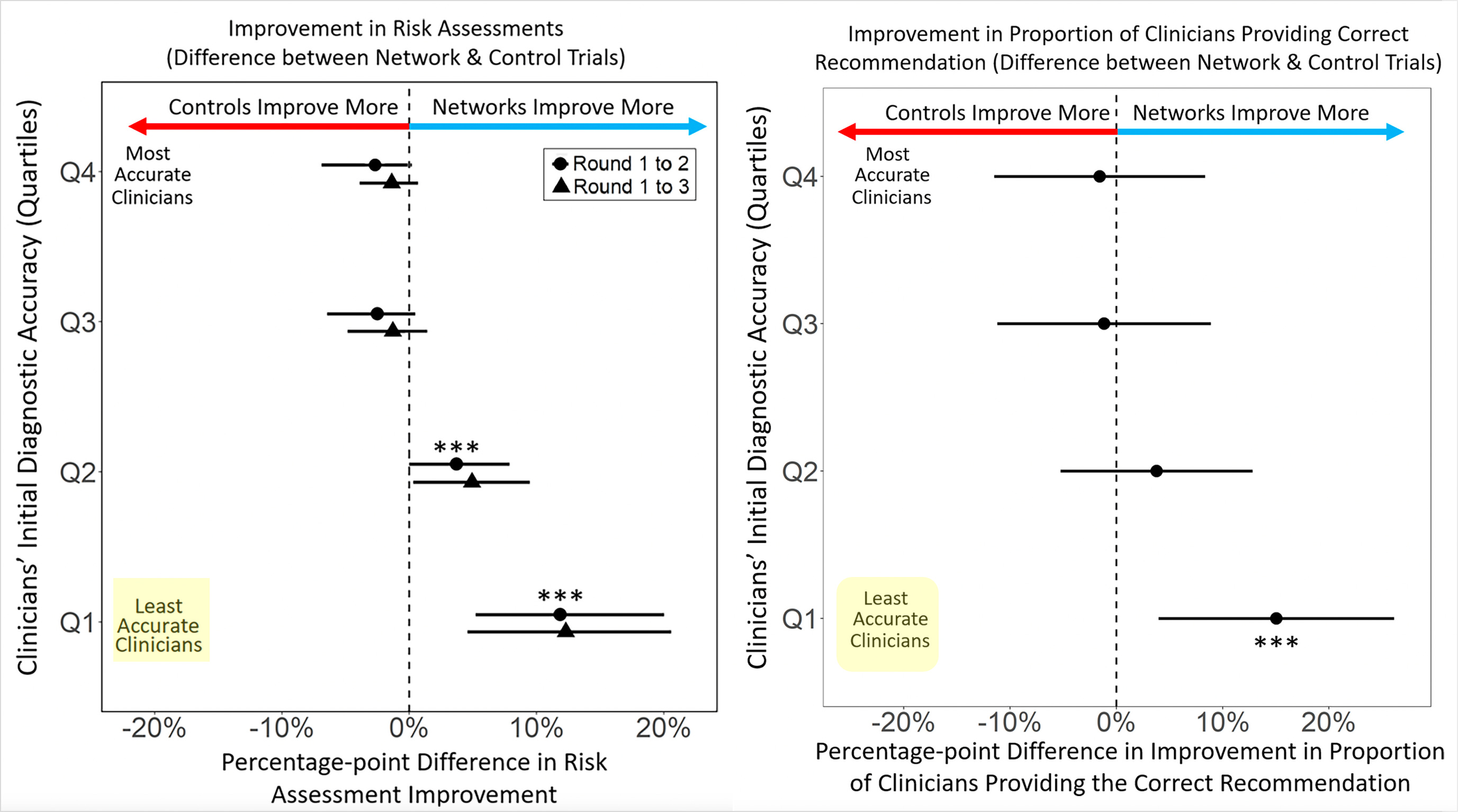
These results highlight the utility of collective human intelligence to promote accuracy of medical diagnoses. There are several smartphone apps that are in current use, such as Figure One or Medscape Consult, that allow clinicians to collaborate with others on difficult diagnoses, but there aren’t data from these apps to show the benefit (and who benefits) as seen in the current randomized trial.
A New Randomized Trial: Collective Human-AI Intelligence?
So can’t collaborating with an A.I. do just as well or better as the collective intelligence gained from other humans? Wouldn’t A.I. provide the ultimate “wisdom of the crowd” after ingesting such voluminous information from Wikipedia, hundred of thousands of books and the Internet? Not so fast.
While there are over 60 randomized trials assessing A.I. in healthcare (along with my colleagues, Ryan Han, Pranav Rajpurkar et al, we have a paper reviewing all of these currently under review) we don’t have much to go on for diagnostic accuracy like the one reviewed above. The expectation has been that the combination of humans and A.I. would indeed yield the best accuracy.
Researchers at MIT and Harvard just published a randomized trial of AI with 180 radiologists . The design was complex (no less all the equations in this paper!) with randomization into 4 information tracks to gauge the accuracy performance for radiologist alone, AI alone and the combination for reading chest X-rays.
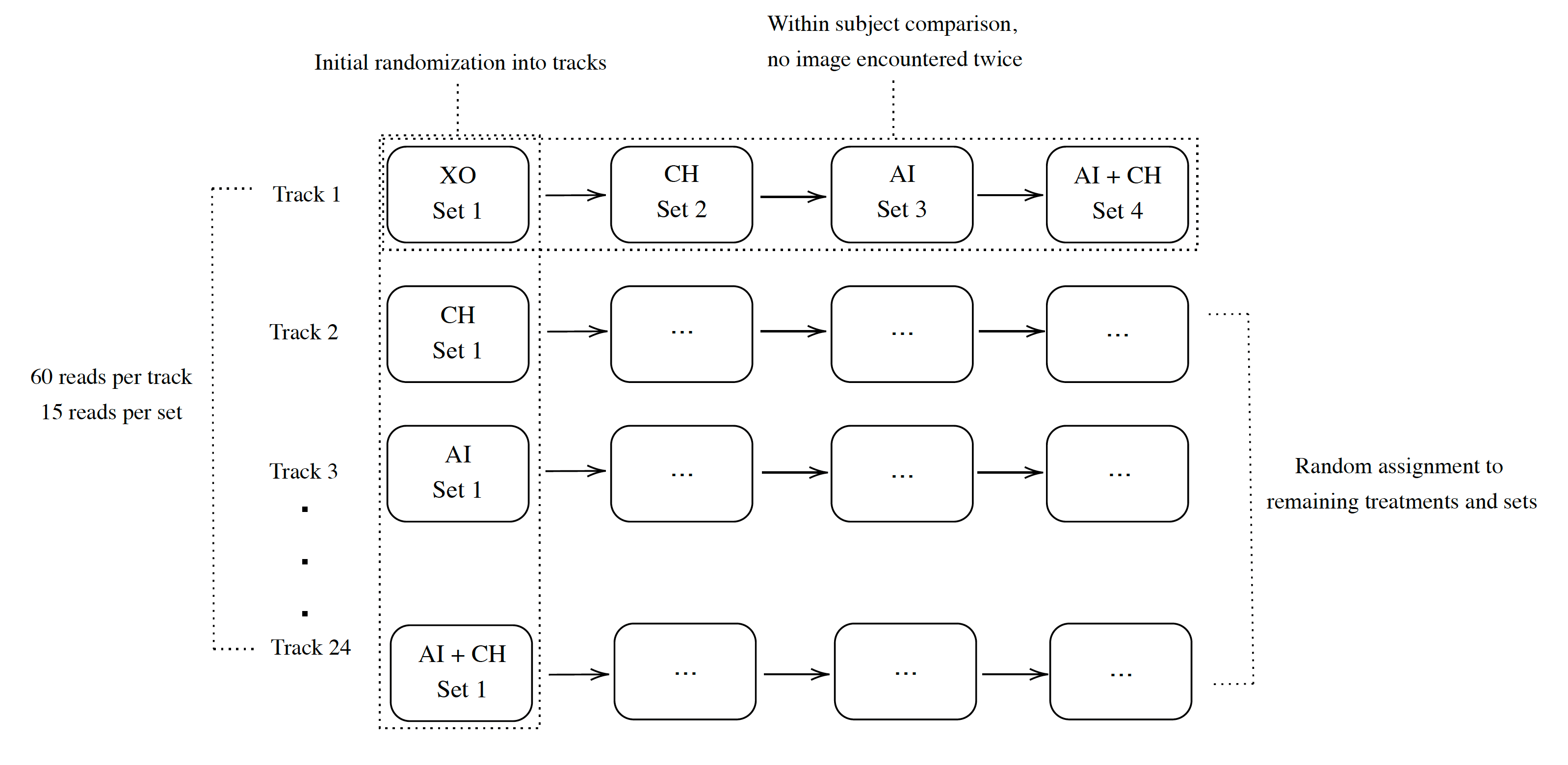
An example of a chest X-ray for which the interpretation was compared for radiologists vs A.I. There was also a track in the design which provided the clinical information (CH=clinical history, in above design graphic).

The results were surprising. The A.I. performed better than the majority, about 66% of radiologists, by two metrics (RMSE-root mean square error and AUROC-area under the receiver-operating characteristic).
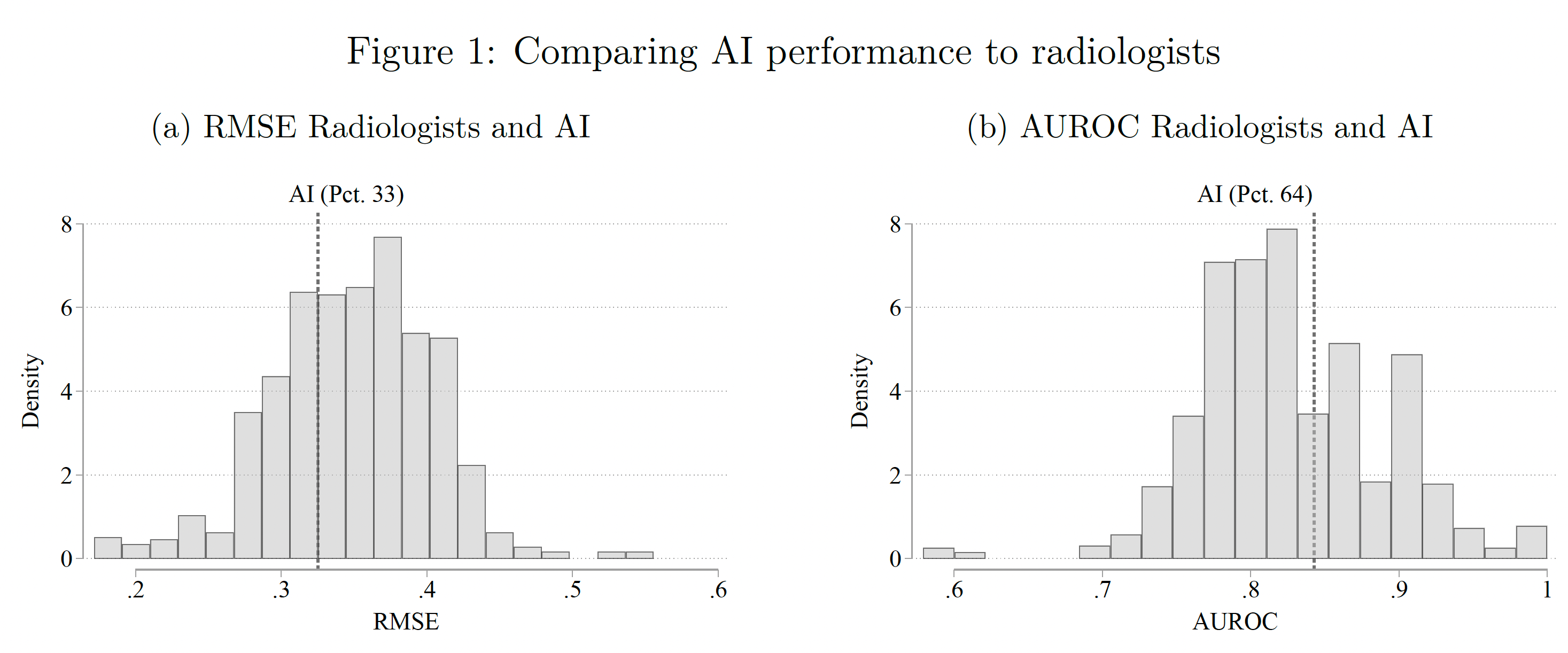
But the radiologists discounted the readings of the A.I. This was attributed to bias: “own-information” bias of the radiologists —which reflect that they feel they know better, leading to “automation neglect,” resulting in their reduction (underweight) of the A.I. probabilities by 30%, as nicely explained in a twitter thread by one of the co-authors, Pranav Rajpurkar, here. While that was the overall result, “the average treatment effects mask important heterogeneity – AI assistance improves performance for a large set of cases, but also decreases performance in many instances.” The explanation for that is when the A.I. was highly confident (e.g. probability >80%), it was more likely to combine with the radiologist for increased accuracy. The clinical information added for the radiologists improved their accuracy, and that CH was not provided to the A.I. We’ve already learned that the more CH information an LLM can ingest, especially from unstructured electronic record text, the more accurate it can get. The conclusion of the paper defied expectations: “Our results demonstrate that, unless the documented mistakes can be corrected, the optimal solution involves assigning cases either to humans or to AI, but rarely to a human assisted by AI.” The irony—many even predicted that humans would simply defer to an A.I.!
That isn’t saying much for humans + A.I. to improve diagnostic accuracy, but there are caveats, such as the lack of using a large language model to provide the clinical information for the A.I. tool. Furthermore, like the prior randomized trials for human-human collective intelligence, these can be viewed as contrived experiments that may well not represent the real world of medicine. The problem is that we don’t yet have any such randomized trials to fulfill what has been widely anticipated.
Further Context
There’s a perception out there, as seen in this tweet (below) yesterday from Vinod Khosla, a venture capital leader and proponent of medical A.I., that A.I. can do superhuman medical things.
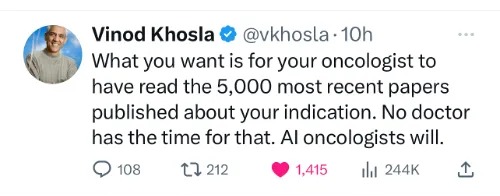
First, there are not “5,000 most recent papers published about your indication.” 😉 Second, the most advanced LLMs today, like GPT-4, have not yet had supervised fine-tuning for the corpus of medical knowledge, no less ingestion of a patient’s full dataset, such as the unstructured text noted in the radiology randomized trial above. Third, we know that the accuracy of medical image interpretation can be markedly improved with deep learning A.I.(compared with expert physicians) but that’s primarily from retrospective studies, A.I. vs humans, not prospective real world assessment (A.I. plus humans, A.I., or humans). Fourth, we know LLMs can and do confabulate. The new study here begs the question for accuracy in medical diagnosis: where is the proof? We’re not talking about finding a colonic polyp via machine vision that is missed by a gastroenterologist, a capability which has been confirmed by multiple randomized trials. I’m referring to making accurate clinical diagnoses, especially complex or uncommon ones, from the history and physical, along with any appropriate tests required.
My prior Ground Truths on A.I. recapped how GPT-4 came up with the diagnosis (or in the differential) for clinicopathologic (CPC) cases in the New England Journal of Medicine at parity with seasoned clinicians was encouraging. But again, that doesn’t provide unequivocal proof that we can fix or improve the diagnostic accuracy issue in real world medical practice. Unfortunately, neither does this simulation study from Google researchers last week in Nature Medicine.
To implement A.I. into medical practice at scale, we need compelling data, especially when it comes to making an accurate medical diagnosis. My friend, Craig Spencer, an emergency room physician, recently wrote an editorial on this matter, concluding: “But until artificial intelligence can develop a gut feeling, honed by working with thousands of patients, a few near-misses, and some humbling cases that stick with you, we’ll need the healing hands of real providers. And that might be forever.”
Yes, we will always need humans-in-the-loop, the healing hands. But to trust the potential role for A.I. to help us deal with the huge problem of diagnostic errors, a desperate unmet need, it requires incontrovertible evidence in the real and often messy world of medical practice. I remain optimistic that we’ll see that eventually, but it’s on us humans to get it done—and soon.
Thanks for reading Ground Truths!
Your free subscription denotes your support of this work. If you decide to become a paid subscriber you should know that all proceeds go to support Scripps Research. That has already helped to bring on several of our summer high school and college interns.