


Medical A.I. is on a tear
Part One summary of recent studies
Since medical A.I. is my main research focus, I try to keep up with all the latest publications and reports. But that has proven increasingly difficult in recent weeks as we’re seeing an acceleration of outputs. I’m going to summarize here (Part One) 3 new deep learning cardiopulmonary imaging studies, one transformer model (aka generative A.I., or large language model, LLM), some progress in virtual scribes and tomorrow (Part Two) a slew of new papers that are coming out.
1. “Your Chest X-Ray Indicates You May Have Diabetes”
Ayis Pyrros and colleagues published an important paper for deep neural network training of chest X-rays (CXRs) to detect Type 2 diabetes, something we would not have anticipated. Over 270,000 CXRs from >160,000 patients were used to develop the model, and then it was prospectively assessed in nearly 10,000 patients.
Below you can see the model performed well independent of race/ethnicity, which is a critical issue that must always be considered. While the overall accuracy (as reflected by AUC 0.84) wasn’t very high (like 0.95 or higher), it’s important to note that CXRs are the most common medical image obtained in the world. If their use can be extended to an unforeseen ability to help detect T2D, that would be welcome.

This is one more example of machine “eyes” (trained by large data inputs) to detect things that human eyes cannot. How did the model detect the potential diagnosis of Type 2 diabetes? To the credit of the researchers, the search for explainability led to finding some of the features that accounted for A.I. detection such as central adiposity and attenuation of the ribs and clavicles (top Figure). Even so, the model accuracy was somewhat better in people with BMI < 25 (AUC 0.89) as compared with those with BMI >25 (AUC 0.84). The authors called this “opportunistic Type 2 diabetes screening” which is apropos, since the diagnosis of diabetes in frequently missed.
2. “Your Chest X-Ray Indicates Your Ejection Fraction May be Low and the Presence of Valve Disease”
For as long as I can remember, we have not considered the chest X-ray as a useful way to estimate a patient’s heart function ,as reflected by ejection fraction (less than or more than 40%). This notion was challenged by Ueda and colleagues in a new paper by using over 22,000 paired CXRs and echocardiograms from multiple institutions to train a model, with external validation (with an AUC of 0.87 for all the findings on ejection fraction, valve disease, and inferior vena cava dilation in the Figure below).
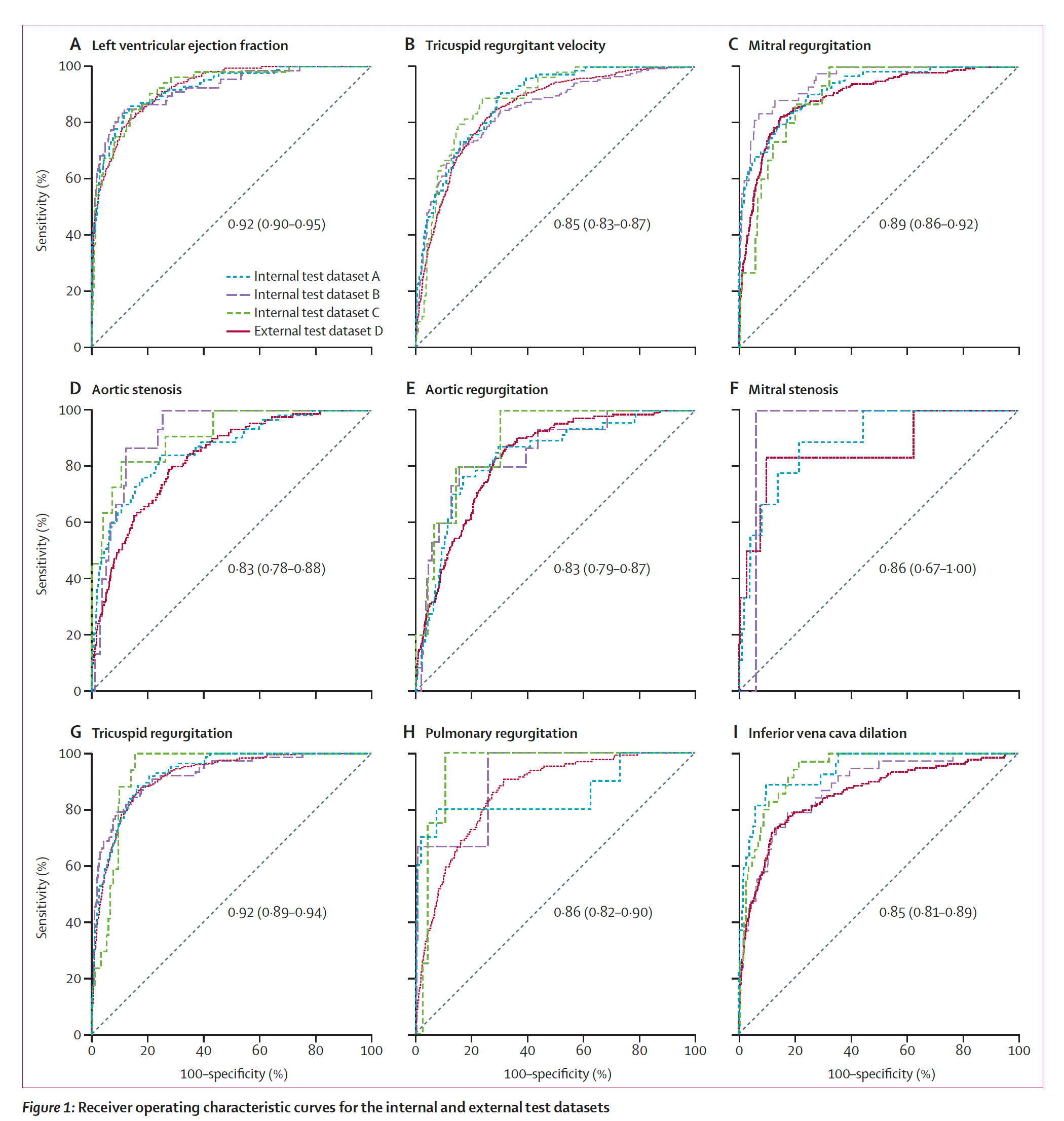
Like the diabetes from CXR study, I would not have anticipated this was possible and consider the work particularly creative and innovative. That is, with CXRs again being the most common medical image obtained in the world, at considerably less expense than an echocardiogram, the practical value of these findings is notable.
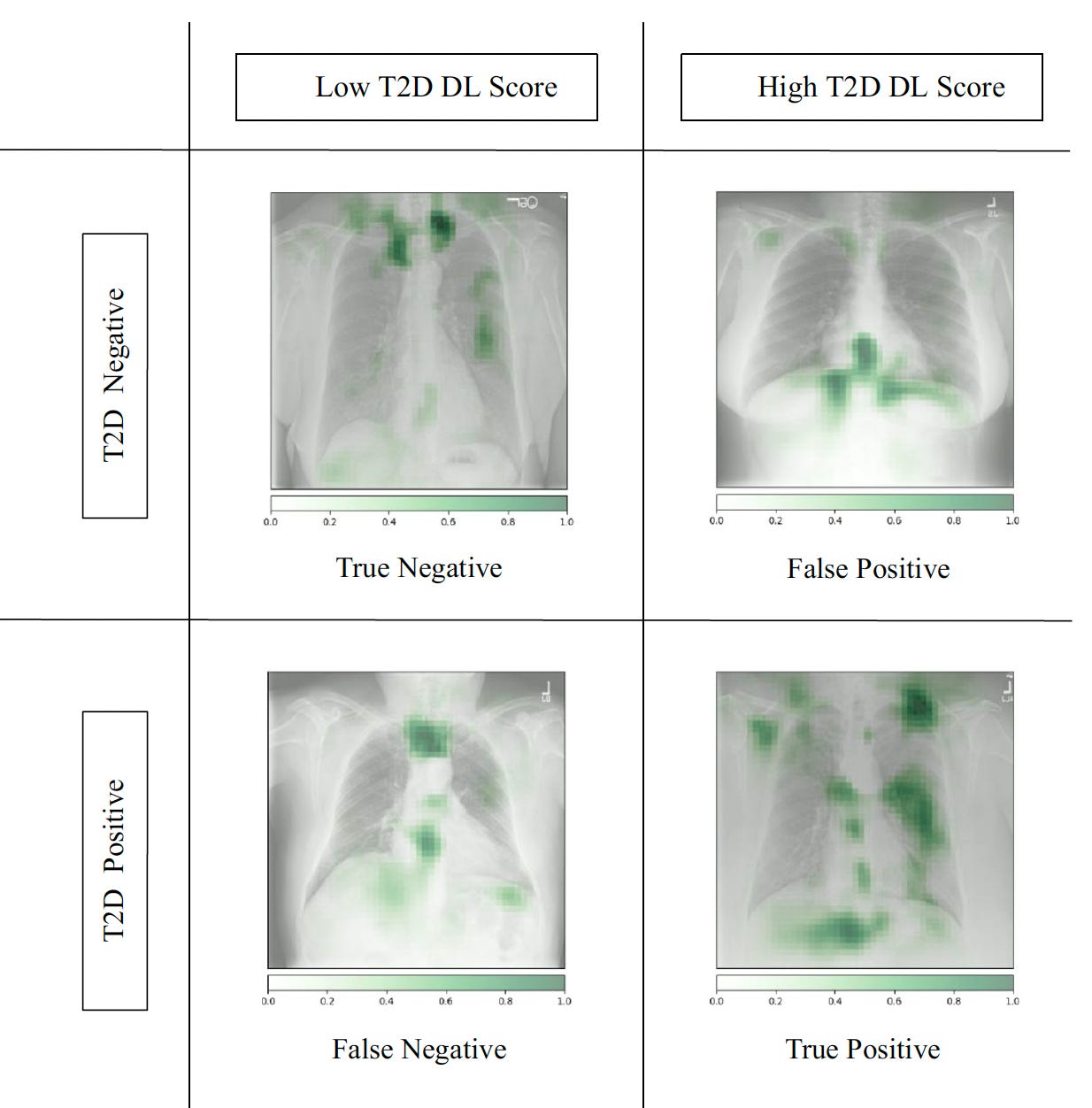
To their credit, these researchers also went after explainability with saliency maps, as shown below. For ejection fraction and each of the other valve/IVC findings (the rest are shown in the supplemental material) the heart shadows shape and contour features provided some of the explanation for how the CXR could impute the echo results.
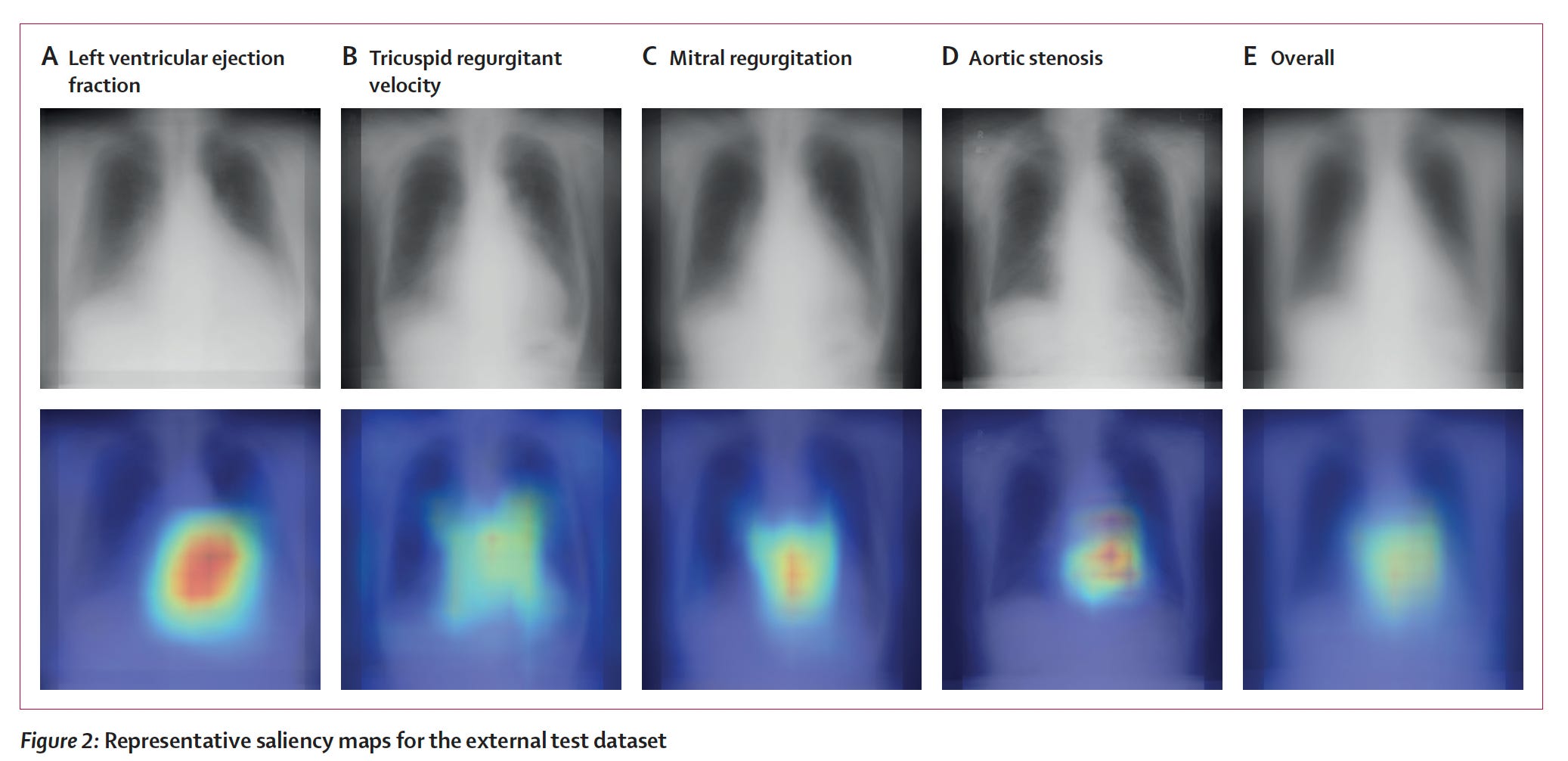
3. “Your Electrocardiogram Shows You Are Having a Heart Attack”
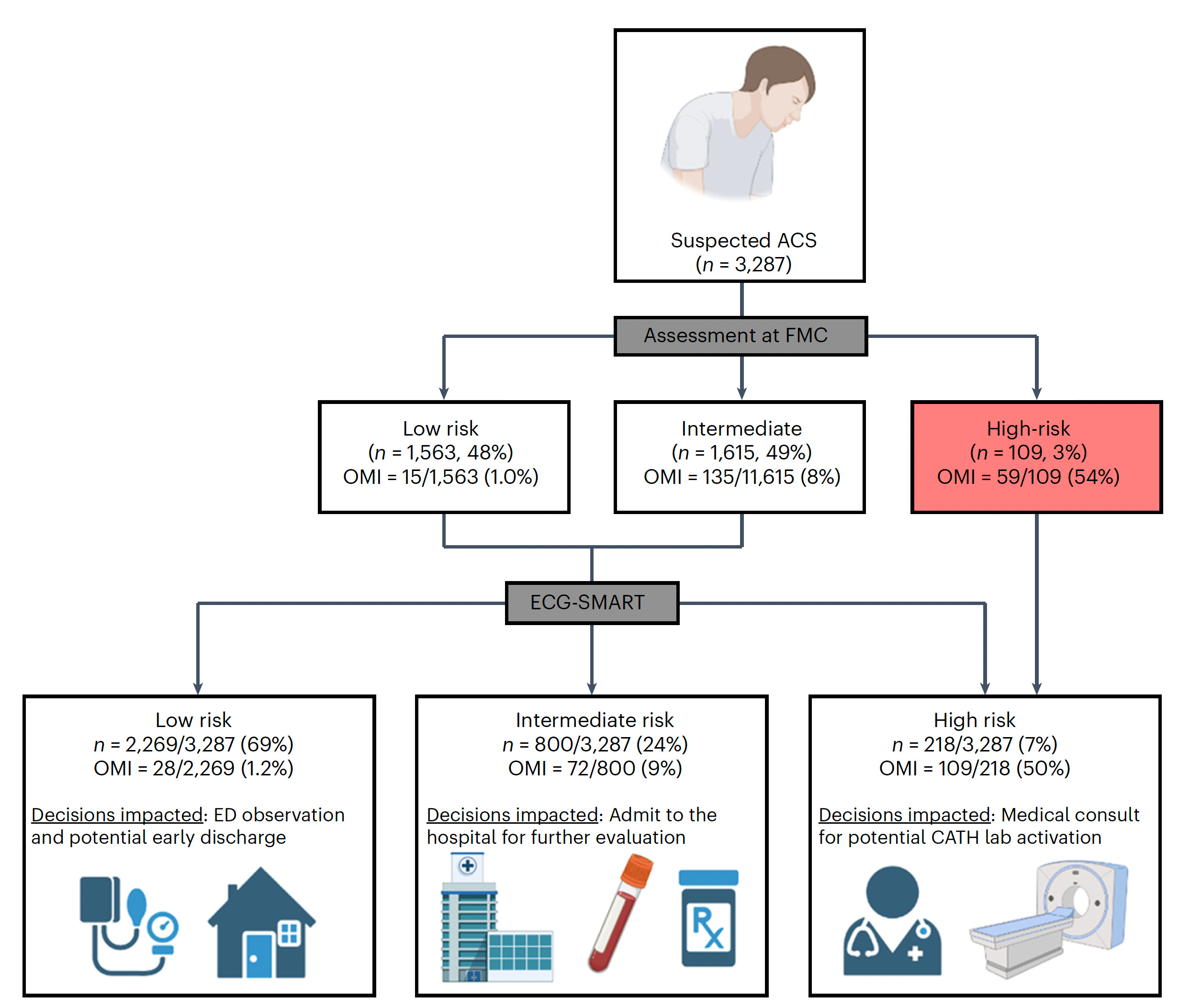
While the ECG is critical in diagnosing a heart attack, many patients who present to an emergency department do not have diagnostic findings. About 30% of presenting patients actually have an acute, occluded (100% blocked) coronary artery without the characteristic ECG ST-segment elevation. Similarly, the initial troponin blood test for evidence of myocardial injury is negative in about 1 in 4 patients who are subsequently diagnosed with acute MI. A new study by Al-Zaiti and colleagues, tackled this issue, with the workflow for model development of a risk score as shown below, with prospective assessment and external validation in independent health systems.
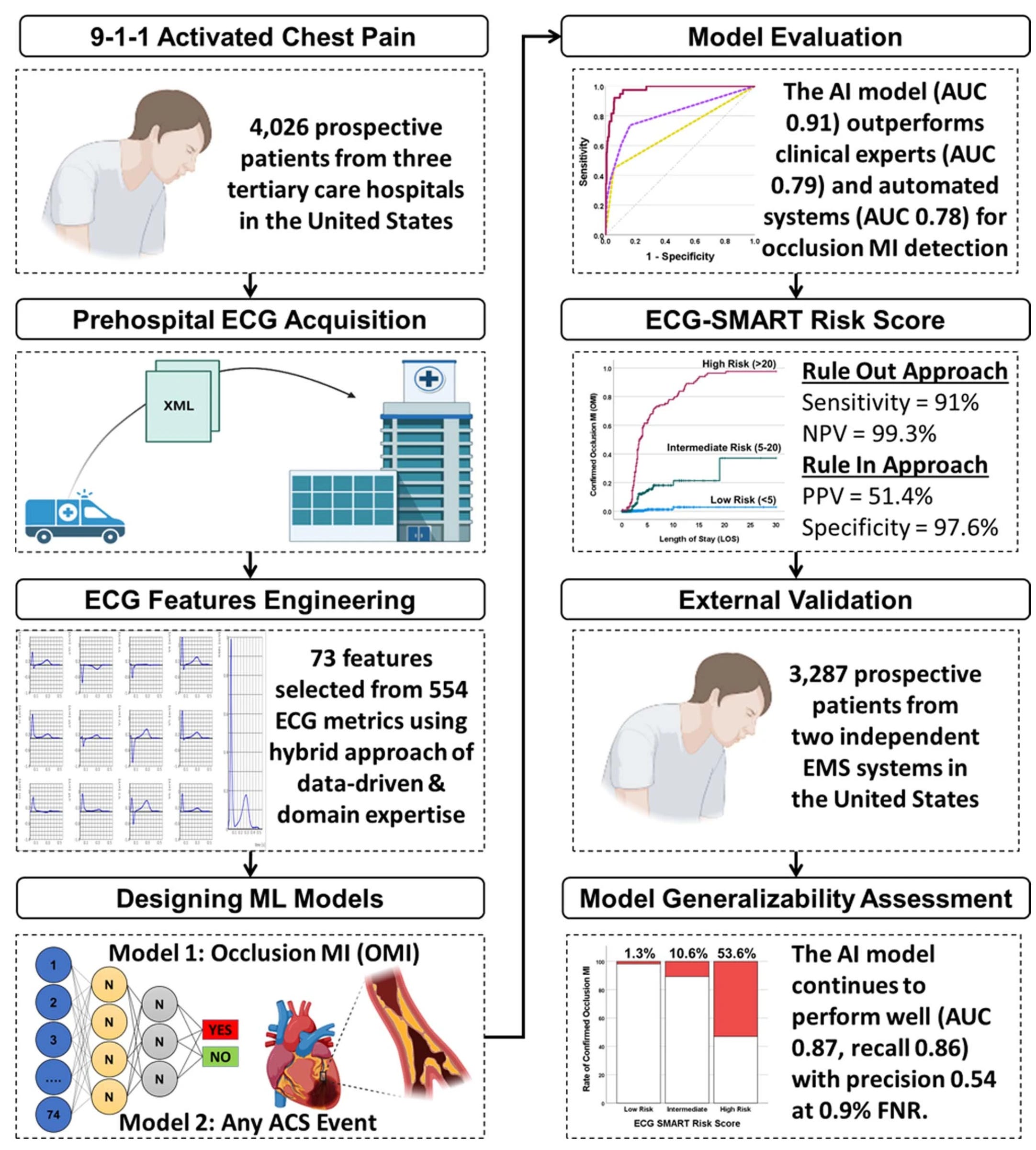
Of note, 1 in 3 patients were correctly reclassified by the “SMART” A.I. derived risk score. Like the other 2 studies above, there were deliberate efforts for explainability, with unraveling of the 25 most important features that drove the accuracy of the model, which outperformed both clinician experts and commercial ECG interpretation systems. A proper assertion in the text: “This is the first study using machine learning methods and novel ECG features to optimize OMI [occlusive heart attack, MI] detection in patients with acute chest pain and negative STEMI [ST elevation MI] pattern on their presenting ECG.”
The important triage implications of the combined algorithm and clinical interpretation are shown below. Further replication of this report and implementation could be a critical step forward in more accurate diagnosis and timely treatment of heart attack patients.
4. Large Language Models are Answering Medical Questions Increasingly Correctly
In a new report by Google AI researchers, Karan Singhal and colleagues, the progression of their large language models from Flan-PaLM to Med-PaLM, was assessed. Beyond the ability for Med-PaLM to exceed the passing threshold for the US Medical Licensing Exam (USMLE) as I previously reviewed, you can see below the substantial increments for correct comprehension, correct retrieval, and evidence of correct reasoning from Flan-PaLM to Med-PaLM for 140 medical questions assessed. Overall, a clinician panel judged 61.9% of Flan-PaLM long-form answers to be aligned with the scientific consensus, compared with 92.6% for Med-PaLM answers; these were approaching parity with the clinician-generated answers (92.9%). But for incorrectness, panel b below shows the inferiority of the A.I. models to clinicians.

While there wasn’t evidence of increased bias for the LLMs. they performed worse for inappropriate/incorrect content and likelihood of possible harm.
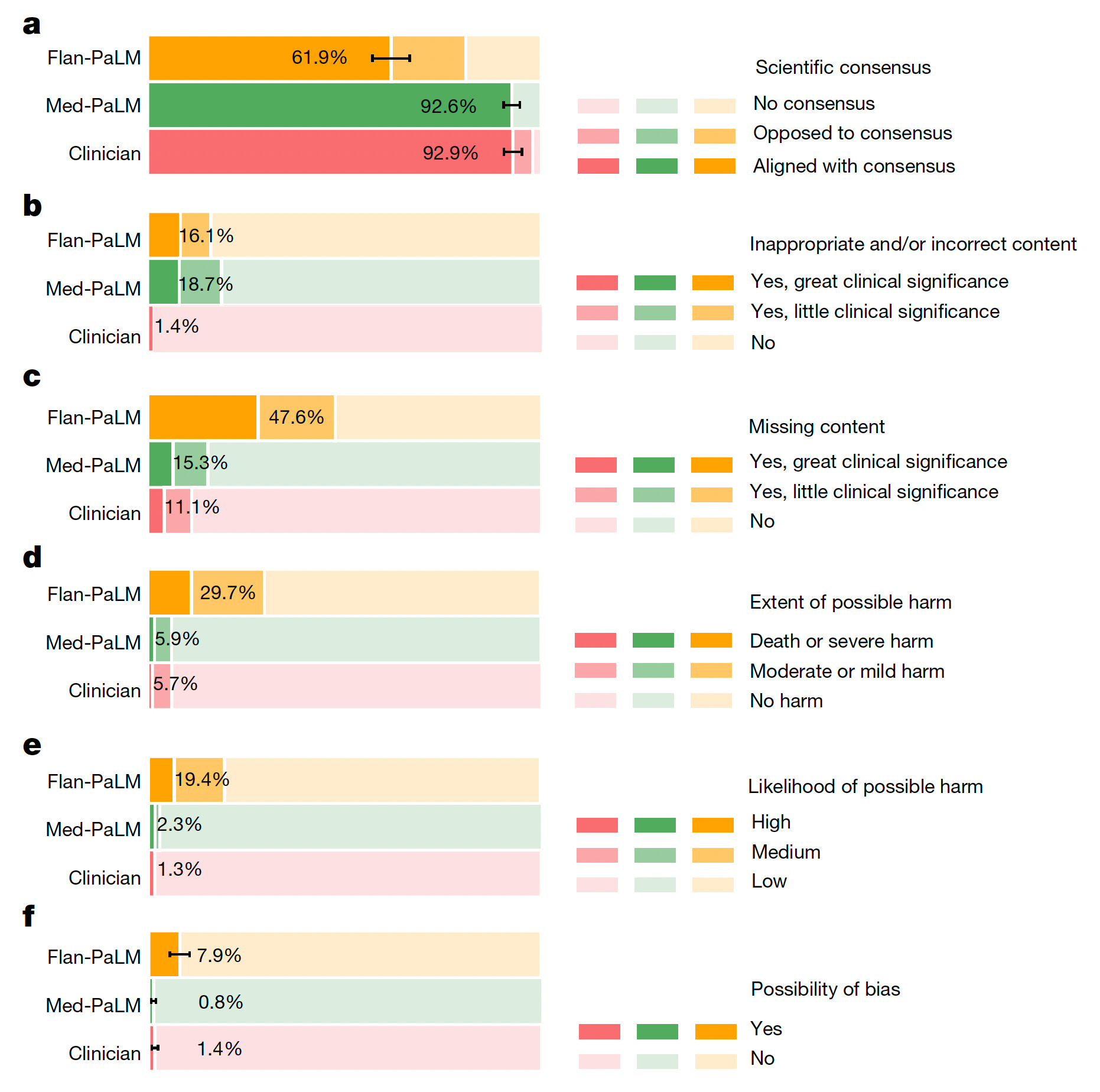
The authors acknowledged the limitations of inferiority to clinicians, concluding “ Our human evaluations reveal limitations of today’s models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLMs for clinical applications.” What is noteworthy is that their Med-PaLM2 model far exceeded performance what was published in the new Nature paper on Med-PaLM, as evident from their May 2023 Med-PALM2 preprint using the USMLE jump in accuracy, shown below.

This suggests that the speed of fine-tuning LLMs is far exceeding that of peer review publications (OK, that’s not saying too much!) and we are clearly going to see considerable more improvements of these LLMs in the times ahead. There’s intense completion between Google and Microsoft, along with other tech titans and “startup” companies with impressive LLMs. A WSJ article this week highlighted Google’s emphasis on health applications.

5. “A.I. Outshines in Health Care, At Paperwork.”
A front-page article in the New York Times spotlighted the process of using conversations during clinic visits to produce notes, treatment plans, and billing, potentially saving a lot of time for physicians.

As Steve Lohr, the journalist, nicely put it: “The best use for generative A.I. in health care, doctors say, is to ease the heavy burden of documentation that takes them hours a day and contributes to burnout.” What is particularly good is that the written, synthetic note can be quickly cross-checked with the words spoken, fostering verifiability and trust for both the doctor and patient. From the article: “The software translates any medical terminology into plain English at about a fourth-grade reading level. It also provides a recording of the visit with “medical moments” color-coded for medications, procedures and diagnoses. The patient can click on a colored tag and listen to a portion of the conversation.” Reducing documentation would be terrific, but such evaluations are now only media reports without prospective peer-reviewed publications. [Full disclosure: one of the 4 companies mentioned in the article is Abridge, for which I am an advisor]. When (and if) there are compelling data, this application of LLMs may be the earliest to be implemented in the clinic. An added advantage is the lack of need for regulatory oversight, a major issue that Bertalan Mesko and I recently reviewed and published this week.
Summary
For this Part One of recent medical A.I. reports, I’ve delved a bit into 3 traditional deep learning models, one transformer LLM paper from today, and the recent media report that lends some promise for reducing the burden of clinical documentation. Please appreciate that all of this is a “work in progress” and that none of these studies are ready for implementation. Nonetheless, they are quite encouraging for a few reasons: (1) Machine eyes are consistently surprising us for what they can see that expert humans can’t (see my previous post on the amazing power of machine eyes), (2) Each of the new studies are trying to get at explainability of their models, which is important, (3) The ability to answer medical questions, for both clinicians and patients, is clearly improving but not yet at any point to be safely and clinically deployable, and (4) LLMs without fine-tuning for medical input may prove particularly useful for helping clinicians reduce their data-clerk functions, and, as mentioned in the last article, one physician, Michelle Thompson, stated “ A.I. has allowed me, as a physician, to be 100 percent present for my patients.” That was the premise of Deep Medicine (the book I published 4 years ago) so hopefully we’ll begin to see the start of it, and the rebuilding the patient-doctor relationship.
Part Two will be tomorrow, hopefully, or sometime very soon.
Thanks for reading, sharing, and subscribing to Ground Truths!
P.S. If you decide to become a paid subscriber, know that all proceeds go to Scripps Research and they have already been used to support many of our high school and college summer interns.