


Medical A.I. is On a Tear, Part Two
This week’s Science Magazine is dedicated to A.I., much of it medical applications and progress. In this post, I’m going to briefly go through those papers, along with other new and relevant work.

A Randomized Trial of Generative A.I.
Before getting into the papers focused on medicine and healthcare, let me touch on one very interesting study on ChatGPT in this issue entitled “Experimental evidence on the productivity effects of generative artificial intelligence.” In a randomized trial of writing tasks, half of 453 college-educated professionals were given support with ChatGPT and the other half were the controls, not getting access. The ChatGPT group’s average time taken was reduced by 40% and the quality (independently adjudicated) increased by 18%. Not only was productivity substantially increased, but job satisfaction was significantly enhanced, as was optimism. Inequality between workers decreased. This is one of (if not) the first published randomized trials of an LLM, and it certainly has some encouraging findings.

Regarding the reduction of inequality, there is a Policy Forum by Ajay Agrawal and colleagues arguing that more automation with A.I. can help, in contrast to the dominant concern that it may be worsened. Using an example in medicine with automation to improve diagnostic capabilities, they write: “If AI automates the higher-wage workers such as doctors, then it might augment other medical professionals and decrease inequality…..By contrast, the wider health care profession—which includes 3 million registered nurses and millions of other professionals such as pharmacists, nurse practitioners, physician assistants, and paramedics—could potentially benefit from AI-driven diagnostics.”
A.I. and Bias in Healthcare
One of the unanticipated outgrowths of machine eyes was the ability to predict race of the patient based on medical images, reported by Judy Gichoya and colleagues in 2022, leading to concerns that AI systems will promote discrimination and exacerbate health care disparities. James Zou, Judy Gichoya and colleagues have a thoughtful essay on this issue that looks at both sides of the ability of AI to predict race variables, pointing out this feature “could be useful for monitoring health care disparity and ensuring that algorithms work well across diverse populations.” In contrast, in a preprint posted this week, Omiye and co-authors argue that large language models will substantially propagate race-based medicine.
It’s too early to know how this will play out, and it certainly remains a serious concern—and not just about race or ethnicity (such as gender, disability, and many other biases). But DeCamp and Lindvall in the new issue have an important piece on mitigating bias, While minimizing bias can be approached through input datasets or the algorithm development teams, that’s insufficient. Their main point is about A.I. implementation—how the models are actually used in patient care—as summarized in the graphic below. They write: “The gaze of AI should be turned on itself. This requires proactive, intentional development of AI tools to identify biases in AI and in its clinical implementation.”

A.I. and Infectious Disease
In this issue, there is a terrific review of the extensive opportunities to use A.I. in the fight against infectious diseases, by Felix Wong and colleagues at MIT and Penn. The multiple ways by which A.I. can facilitate drug discovery of new agents to counter antimicrobial resistance, from screening vast libraries to predicting structures via AlphaFold, also lends itself to improvements in vaccines. Facilitating molecular testing for rapid diagnostic testing of pathogens, and use of synthetic biology to enhance the understanding of the biology of infections, both of which are enhanced with A.I. tools, are discussed at length.
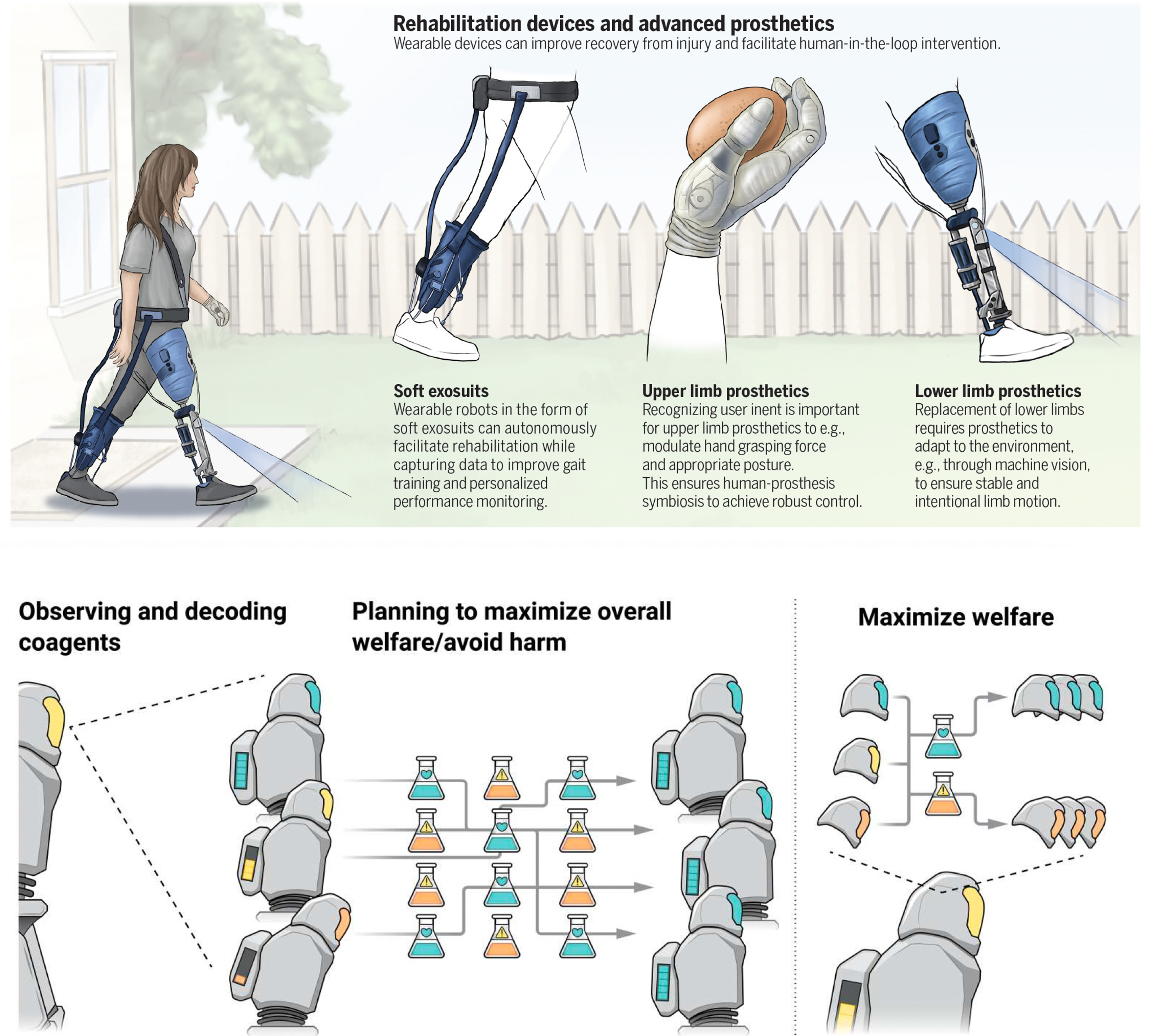
Robots for Rehab and Promoting Empathy
Two papers, one in the Science issue on medical robotics, and the other in the sister journal, Science Robotics on robots to promote empathy (or at the very least not be antisocial). The medical robotics review gets briefly into robotic imaging, robotic surgery (not a new topic but getting more sophisticated), and the marked improvements in robotic prosthetics (upper panel, Figure below).
The unanticipated use of A.I. to promote empathy is a topic of great interest, which I previously reviewed in context of GPT-4 (such as coaching doctors). In the robotic empathy (what would be considered an oxymoron, for sure) paper (lower panel, Figure below), Christov-Moore and colleagues lay out the path towards the agent predicting a person’s behavior and affective state, but also point out that achieving “the approximation of affective empathy” will be quite challenging.
Chatbots Instead of Research Participants?
A provocative essay by Matthew Hutson, one of the leading journalists covering A.I., builds on a recent brief paper that raised the question about LLMs replacing human participants for social/psychological science research—via an anecdote with GPT 3.5 answering >460 questions compared with humans with a correlation coefficient of 0.95. Marcel Benz, a cognitive scientist at the Max-Planck Institute, said, “It is plausible that we will have a system within a few years that can just be placed into any experiment and will produce behavior indistinguishable from human behavior.”
Given all the issues that have plagued social science research in recent years with respect to lack of reproducibility, I don’t see this is likely. As mentioned above, the LLMs have big issues with biases and inconsistencies (e.g. give GPT-4 the same prompt and get different responses). Moreover, this seems quite unlikely in other types of medical research.
Summary
There’s a lot packed into the Science A.I. issue and I certainly haven’t covered it all, with additional paper on topics such as games, art, and copyright. But one brief essay that I want to finish up on is Melanie Mitchell’s (a leading A.I. expert and Professor at Santa Fe Institute, with an upcoming podcast here) essay: “How do we know how smart AI systems are?” It’s the first of a new series called “Expert Voices” at Science ( I will be participating in this and will have a column on medical A.I. later this Fall). Prof Mitchell dissects the recent bold claims about LLM super intelligence and points out “Taken together, these problems make it hard to conclude—from the evidence given—that AI systems are now or soon will match or exceed human intelligence.” This is an essential and balanced perspective to keep in mind—that there’s a need for far more transparency of the models to evaluate any claims of high-order machine intelligence.
I hope you’ve found these two newsletters (Part One and Two) to be helpful and informative. You can count on me posting many future Ground Truths on important matters, advances, and liabilities of medical A.I.
With much appreciation for your reading, and subscribing to Ground Truths.