


When Medical A.I. is Lifesaving
Counterbalanced by some disappointments
Our gold standard of assessing efficacy in medicine is a large-scale randomized trial. Last week we reviewed all 88 published randomized medical A.I. trials. Most were targeting intermediate endpoints, such as detection of a colon polyp or an abnormal mammogram. None were focused on reducing mortality as the primary endpoint.
Today that changed. In a paper published at Nature Medicine, nearly 16,000 patients at 2 hospitals in Taiwan were randomly assigned to their physician getting an AI alert of their patient’s electrocardiogram compared to conventional care (single-blind design), with the primary endpoint of all-cause mortality at 90 days.
The main results are summarized below. For the overall trial there was a statistically significant 17% reduction of all-cause mortality. The pre-specified high-risk ECG group was where almost all the benefit (note significant interaction term, P=0.026) was seen: a 31% reduction of deaths, and an absolute 7 per 100 lives saved. That’s remarkable and as good or better than our most effective medical treatments (e.g. statins for secondary prevention).
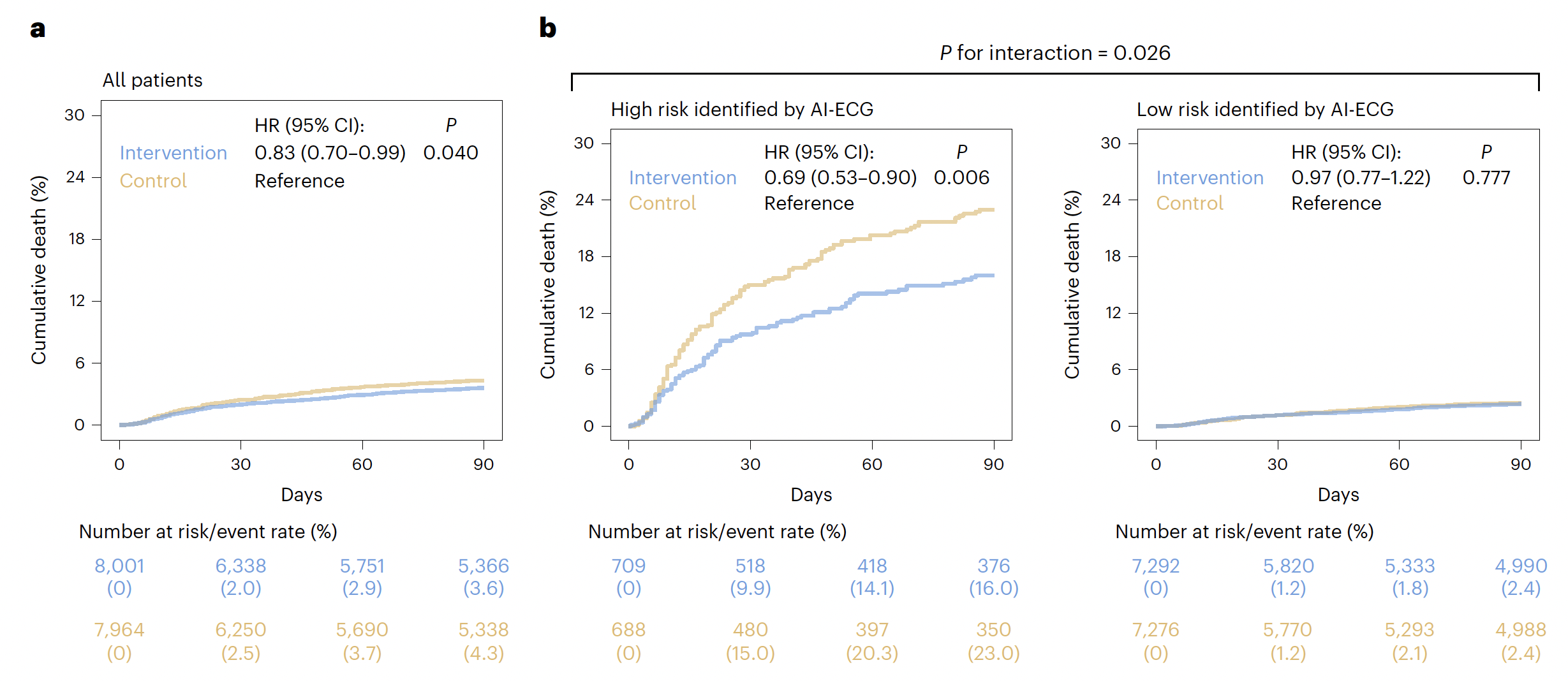
The effect was consistent in direction and magnitude across all subgroups, as seen below

A schematic for the 2 arms of the trial

The high-risk group was determined by a score that combined clinical and ECG features, as shown in these graphs

The main limitation of the trial was inability to determine the precise mechanism of benefit for reduction of mortality. The AI-alert typically led to transfer to intensive care unit and heightened awareness of risk, and these high-risk patients died from a variety of causes, not just heart attack or arrhythmias.
This represents a major milestone in medical A.I. While previous randomized trials have shown improved detection or accuracy endpoints, this one takes it a big step further.
Flanked by Some Disappointments
While the new trial was a real world prospective study using deep learning (not a transformer model), most recent reports are focused on the utility of generative A.I. and are not real world medical practice, but contrived reports using case scenarios or patient actors.
There were 4 such publications in the past week.
Large Language Models in Clinical Oncology
Over 2,000 oncology questions were posed to 5 generative A.I. models and only 1 reached the previously established human benchmark (>50%) for performance (GPT-4). All had significant error rates.

A small randomized study by UCSD assessed whether generative A.I. could reduce writing time replies to patients—it failed to do that, and actually increased time to reply with longer length. The physicians liked the “empathic tone” of the replies. These were draft replies not actually sent to patients.

Assessment of generative A.I. for automated coding. This was supposed to be a sweet spot for A.I., but in a study at Mount Sinai of >7,600 diagnostic codes (ICD) and >3,600 procedure (CPT) codes comparing 4 models, all models performed poorly (GPT-4 was the best vs Gemini Pro, GPT 3.5, Llama2))

LLM response to medical questions on cancer care, a simulation study comparing human manual draft vs LLM, and LLM-assisted, found an important safety signal. Specifically, “It was felt by the assessing physicians that the LLM drafts posed a risk of severe harm in 11 (7·1%) of 156 survey responses, and death in one (0·6%) survey response.”
←can’t get rid of this!





Context
Progress in medical A.I. won’t occur in a straight line. One big step forward, 4 backwards. It’s exciting to see the reduction of mortality in a large, prospective, real-world randomized trial, while at the same time sobering to see 4 studies published that question whether we’re ready for LLMs in medical practice (and even coding). It’s still very early in the era of A.I. in medicine, especially with LLMs, but clearly the more trials like the one published today, the better. Without such compelling evidence, there can’t be meaningful progress and implementation. We need a lot more!
Thanks for reading and subscribing to Ground Truths!
The Ground Truths newsletters and podcasts are all free, open-access, without ads.
Voluntary paid subscriptions all go to support Scripps Research. Many thanks for that—they greatly helped fund our summer internship programs for 2023 and 2024.
Note: you can select preferences to receive emails about newsletters, podcasts, or all I don’t want to bother you with an email for content that you’re not interested in.
Comments are welcome from all subscribers.
Appreciate your always balanced analysis.
A.I. is often conflated with with LLM or machine learning. Aggregation, synthesizing & estimating I would not describe as A.I.
"For the overall trial there was s statistically significant 17% reduction of all-cause mortality. " - there's a typo; "a" statistically significant.