

“We haven't invested this much money into an infrastructure like this really until you go back to the pyramids”—Kate Crawford
Transcript with links to audio and external links. Ground Truths podcasts are on Apple and Spotify. The video interviews are on YouTube
Eric Topol (00:06):
Well, hello, this is Eric Topol with Ground Truths, and I'm really delighted today to welcome Kate Crawford, who we're very lucky to have as an Australian here in the United States. And she's multidimensional, as I've learned, not just a scholar of AI, all the dimensions of AI, but also an artist, a musician. We're going to get into all this today, so welcome Kate.
Kate Crawford (00:31):
Thank you so much, Eric. It's a pleasure to be here.
Eric Topol (00:34):
Well, I knew of your work coming out of the University of Southern California (USC) as a professor there and at Microsoft Research, and I'm only now learning about all these other things that you've been up to including being recognized in TIME 2023 as one of 100 most influential people in AI and it's really fascinating to see all the things that you've been doing. But I guess I'd start off with one of your recent publications in Nature. It was a world view, and it was about generative AI is guzzling water and energy. And in that you wrote about how these large AI systems, which are getting larger seemingly every day are needing as much energy as entire nations and the water consumption is rampant. So maybe we can just start off with that. You wrote a really compelling piece expressing concerns, and obviously this is not just the beginning of all the different aspects you've been tackling with AI.

Exponential Growth, Exponential Concerns
Kate Crawford (01:39):
Well, we're in a really interesting moment. What I've done as a researcher in this space for a very long time now is really introduce a material analysis of artificial intelligence. So we are often told that AI is a very immaterial technology. It's algorithms in the cloud, it's objective mathematics, but in actual fact, it comes with an enormous material infrastructure. And this is something that I took five years to research for my last book, Atlas of AI. It meant going to the mines where lithium and cobalt are being extracted. It meant going into the Amazon fulfillment warehouses to see how humans collaborate with robotic and AI systems. And it also meant looking at the large-scale labs where training data is being gathered and then labeled by crowd workers. And for me, this really changed my thinking. It meant that going from being a professor for 15 years focusing on AI from a very traditional perspective where we write papers, we're sitting in our offices behind desks, that I really had to go and do these journeys, these field trips, to understand that full extractive infrastructure that is needed to run AI at a planetary scale.

(02:58):
So I've been keeping a very close eye on what would change with generative AI and what we've seen particularly in the last two years has been an extraordinary expansion of the three core elements that I really write about in Atlas, so the extraction of data of non-renewable resources, and of course hidden labor. So what we've seen, particularly on the resources side, is a gigantic spike both in terms of energy and water and that's often the story that we don't hear. We're not aware that when we're told about the fact that there gigantic hundred billion computers that are now being developed for the next stage of generative AI that has an enormous energy and water footprint. So I've been researching that along with many others who are now increasingly concerned about how we might think about AI more holistically.
Eric Topol (03:52):
Well, let's go back to your book, which is an extraordinary book, the AI Atlas and how you dissected not just the well power of politics and planetary costs, but that has won awards and it was a few years back, and I wonder so much has changed since then. I mean ChatGPT in late 2022 caught everybody off guard who wasn't into this knowing that this has been incubating for a number of years, and as you said, these base models are just extraordinary in every parameter you can think about, particularly the computing resource and consumption. So your concerns were of course registered then, have they gone to exponential growth now?
Kate Crawford (04:45):
I love the way you put that. I think you're right. I think my concerns have grown exponentially with the models. But I was like everybody else, even though I've been doing this for a long time and I had something of a heads up in terms of where we were moving with transformer models, I was also quite taken aback at the extraordinary uptake of ChatGPT back in November 2022 in fact, gosh, it still feels like yesterday it's been such an extraordinary timescale. But looking at that shift to a hundred million users in two months and then the sort of rapid competition that was emerging from the major tech companies that I think really took me by surprise, the degree to which everybody was jumping on the bandwagon, applying some form of large language model to everything and anything suddenly the hammer was being applied to every single nail.
(05:42):
And in all of that sound and fury and excitement, I think there will be some really useful applications of these tools. But I also think there's a risk that we apply it in spaces where it's really not well suited that we are not looking at the societal and political risks that come along with these approaches, particularly next token prediction as a way of generating knowledge. And then finally this bigger set of questions around what is it really costing the planet to build these infrastructures that are really gargantuan? I mean, as a species, we haven't invested this much money into an infrastructure like this really until you go back to the pyramids, you really got to go very far back to say that type of just gargantuan spending in terms of capital, in terms of labor, in terms of all of the things are required to really build these kinds of systems. So for me, that's the moment that we're in right now and perhaps here together in 2024, we can take a breath from that extraordinary 18 month period and hopefully be a little more reflective on what we're building and why and where will it be best used.
Propagation of Biases
Eric Topol (06:57):
Yeah. Well, there's so many aspects of this that I'd like to get into with you. I mean, one of course, you're as a keen observer and activist in this whole space, you've made I think a very clear point about how our culture is mirrored in our AI that is our biases, and people are of course very quick to blame AI per se, but it seems like it's a bigger problem than just that. Maybe you could comment about, obviously biases are a profound concern about propagation of them, and where do you see where the problem is and how it can be attacked?
Kate Crawford (07:43):
Well, it is an enormous problem, and it has been for many years. I was first really interested in this question in the era that was known as the big data era. So we can think about the mid-2000s, and I really started studying large scale uses of data in scientific applications, but also in what you call social scientific settings using things like social media to detect and predict opinion, movement, the way that people were assessing key issues. And time and time again, I saw the same problem, which is that we have this tendency to assume that with scale comes greater accuracy without looking at the skews from the data sources. Where is that data coming from? What are the potential skews there? Is there a population that's overrepresented compared to others? And so, I began very early on looking at those questions. And then when we had very large-scale data sets start to emerge, like ImageNet, which was really perhaps the most influential dataset behind computer vision that was released in 2009, it was used widely, it was freely available.
(09:00):
That version was available for over a decade and no one had really looked inside it. And so, working with Trevor Paglen and others, we analyzed how people were being represented in this data set. And it was really quite extraordinary because initially people are labeled with terms that might seem relatively unsurprising, like this is a picture of a nurse, or this is a picture of a doctor, or this is a picture of a CEO. But then you look to see who is the archetypical CEO, and it's all pictures of white men, or if it's a basketball player, it's all pictures of black men. And then the labeling became more and more extreme, and there are terms like, this is an alcoholic, this is a corrupt politician, this is a kleptomaniac, this is a bad person. And then a whole series of labels that are simply not repeatable on your podcast.
(09:54):
So in finding this, we were absolutely horrified. And again, to know that so many AI models had trained on this as a way of doing visual recognition was so concerning because of course, very few people had even traced who was using this model. So trying to do the reverse engineering of where these really problematic assumptions were being built in hardcoded into how AI models see and interpret the world, that was a giant unknown and remains to this day quite problematic. We did a recent study that just came out a couple of months ago looking at one of the biggest data sets behind generative AI systems that are doing text to image generation. It's called LAION-5B, which stands for 5 billion. It has 5 billion images and text captions drawn from the internet. And you might think, as you said, this will just mirror societal biases, but it's actually far more weird than you might imagine.
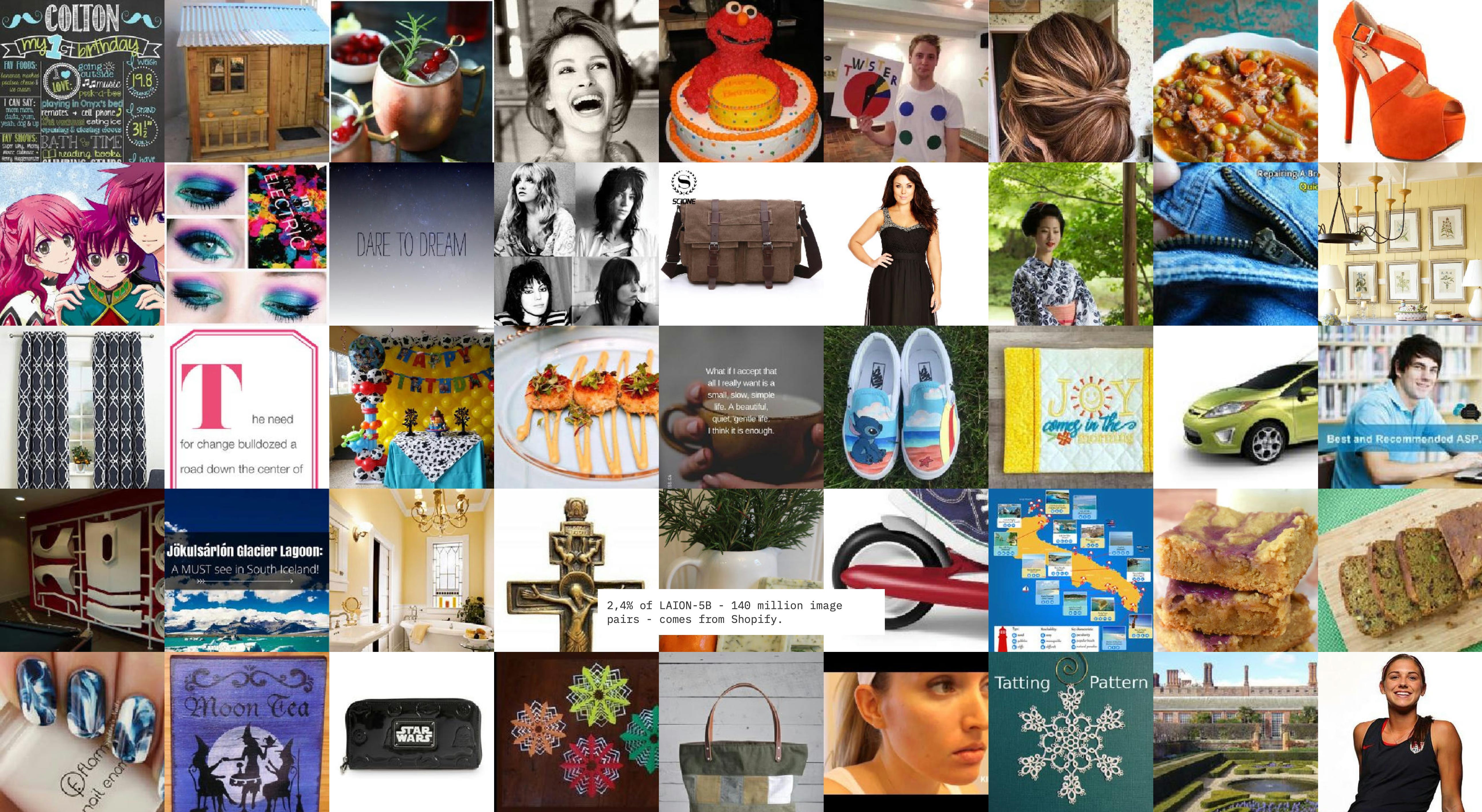
(10:55):
It's not a representative sample even of the internet because particularly for these data sets that are now trying to use the ALT tags that are used around images, who uses ALT tags the most on the internet? Well, it's e-commerce sites and it's often stock image sites. So what you'll see and what we discovered in our study was that the vast majority of images and labels are coming from sites like Shopify and Pinterest, these kind of shopping aspirational collection sites. And that is a very specific way of seeing the world, so it's by no means even a perfect mirror. It's a skewed mirror in multiple ways. And that's something that we need to think of particularly when we turn to more targeted models that might be working in say healthcare or in education or even in criminal justice, where we see all sorts of problems emerge.
Exploiting Humans for RLHF
Eric Topol (11:51):
Well, that's really interesting. I wonder to extend that a bit about the human labor side of this. Base models are tweaked, fine-tuned, and one of the ways to do that, of course is getting people to weigh in. And this has been written about quite a bit about how the people that are doing this can be exploited, getting wages that are ridiculously weak. And I wonder if you could comment about that because in the ethics of AI, this seems to be one of the many things that a lot of people don't realize about reinforcement learning.
Kate Crawford (12:39):
Oh, I completely agree. It's quite an extraordinary story. And of course now we have a new category of crowd labor that's called reinforcement learning with human feedback or RLHF. And what was discovered by multiple investigations was that these laborers are in many cases paid less than $2 an hour in very exploitative conditions, looking at results that in many cases are really quite horrifying. They could be accounts of murder, suicide, trauma, this can be visual material, it can be text-based material. And again, the workers in these working for these companies, and again, it's often contract labor, it's not directly within a tech company, it's contracted out. It's very hidden, it's very hard to research and find. But these laborers have been experiencing trauma and are really now in many cases bringing lawsuits, but also trying to unionize and say, these are not acceptable conditions for people to be working under.
(13:44):
So in the case of OpenAI, it was found that it was Kenyan workers who were doing this work for just poverty wages, but it's really across the board. It's so common now that humans are doing the hard work behind the scenes to make these systems appear autonomous. And that's the real trap that we're being told that this is the artificial intelligence. But in actual fact, what Jeff Bezos calls Mechanical Turk is that it's artificial, artificial intelligence otherwise known as human beings. So that is a very significant layer in terms of how these systems work that is often unacknowledged. And clearly these workers in many cases are muzzled from speaking, they're not allowed to talk about what they do, they can't even tell their families. They're certainly prevented from collective action, which is why we've seen this push towards unionization. And finally, of course, they're not sharing in any of the profits that are being generated by these extraordinary new systems that are making a very small number of people, very wealthy indeed.
Eric Topol (14:51):
And do you know if that's improving or is it still just as bad as it has been reported? It's really deeply concerning to see human exploitation, and we all know well about sweatshops and all that, but here's another version, and it's really quite distressing.
Kate Crawford (15:09):
It really is. And in fact, there have been several people now working to create really almost like fair work guidelines. So Oxford has the sort of fair work initiative looking specifically at crowd work. They also have a rating system where they rate all of the major technology companies for how well they're treating their crowd laborers. And I have to say the numbers aren't looking good in the last 12 months, so I would love to see much more improvement there. We are also starting to see legislation be tabled specifically on this topic. In fact, Germany was one of the most recent to start to explore how they would create a strong legislative backing to make sure that there's fair labor conditions. Also, Chile was actually one of the first to legislate in this space, but you can imagine it's very difficult to do because it's a system that is operating under the radar through sort of multiple contracted chains. And even some of the people within tech companies will tell me it's really hard to know if they're working with a company that's doing this in the right way and paying people well. But frankly, I'd like to see far greater scrutiny otherwise, as you say, we're building on this system, which looks like AI sweatshops.
Eric Topol (16:24):
Yeah, no, I think people just have this illusion that these machines are doing everything by themselves, and that couldn't be further from the truth, especially when you're trying to take it to the next level. And there's only so much human content you can scrape from the internet, and obviously it needs additional input to take it to that more refined performance. Now, besides your writing and being much of a conscience for AI, you're also a builder. I mean, I first got to know some of your efforts through when you started the AI Now Institute. Maybe you can tell us a bit about that. Now you're onto the Knowing Machines Project and I don't know how many other projects you're working on, so maybe you can tell us about what it's like not just to be a keen observer, but also one to actually get initiatives going.
Kate Crawford (17:22):
Well, I think it's incredibly important that we start to build interdisciplinary coalitions of researchers, but sometimes even beyond the academic field, which is where I really initially trained in this space, and really thinking about how do we involve journalists, how do we involve filmmakers, how do we involve people who will look at these issues in really different ways and tell these stories more widely? Because clearly this really powerful shift that we're making as a society towards using AI in all sorts of domains is also a public issue. It's a democratic issue and it's an issue where we should all be able to really see into how these systems are working and have a say in how they'll be impacting our lives. So one of the things that I've done is really create research groups that are interdisciplinary, starting at Microsoft Research as one of the co-founders of FATE, a group that stands for fairness, accountability, transparency and ethics, and then the AI Now Institute, which was originally at NYU, and now with Knowing Machines, which is an international group, which I've been really delighted to build, rather than just purely focusing on those in the US because of course these systems are inherently transnational, they will be affecting global populations.
(18:42):
So we really need to think about how do you bring people from very different perspectives with different training to ask this question around how are these systems being built, who is benefiting and who might be harmed, and how can we address those issues now in order to actually prevent some of those harms and prevent the greatest risks that I see that are possible with this enormous turn to artificial intelligence everywhere?
Eric Topol (19:07):
Yeah, and it's interesting how you over the years are a key advisor, whether it's the White House, the UN or the European Parliament. And I'm curious about your experience because I didn't know much about the Paris ENS. Can you tell us about you were Visiting Chair, this is AI and Justice at the École Normale Supérieure (ENS), I don’t know if I pronounce that right. My French is horrible, but this sounds like something really interesting.
Kate Crawford (19:42):
Well, it was really fascinating because this was the first time that ENS, which is really one of the top research institutions in Europe, had turned to this focus of how do we contend with artificial intelligence, not just as a technical question, but as a sort of a profound question of justice of society of ethics. And so, I was invited to be the first visiting chair, but tragically this corresponded with the start of the pandemic in 2020. And so, it ended up being a two-year virtual professorship, which is really a tragedy when you’re thinking about spending time in Paris to be spending it on Zoom. It’s not quite the same thing, but I had the great fortune of using that time to assemble a group of scholars around the world who were looking at these questions from very different disciplines. Some were historians of science, others were sociologists, some were philosophers, some were machine learners.
(20:39):
And really essentially assembled this group to think through some of the leading challenges in terms the potential social impacts and current social impacts of these systems. And so, we just recently published that through the academies of Science and Engineering, and it’s been almost like a template for thinking about here are core domains that need more research. And interestingly, we’re at that moment, I think now where we can say we have to look in a much more granular fashion beyond the hype cycles, beyond the sense of potential, the enormous potential upside that we’re always hearing about to look at, okay, how do these systems actually work now? What kinds of questions can we bring into the research space so that we’re really connecting the ideas that come traditionally from the social sciences and the humanistic disciplines into the world of machine learning and AI design. That’s where I see the enormous upside that we can no longer stay in these very rigorously patrolled silos and to really use that interdisciplinary awareness to build systems differently and hopefully more sustainably as well.
Is Working At Microsoft A Conflict?
Eric Topol (21:55):
Yeah, no, that’s what I especially like about your work is that you’re not a doomsday person or force. You’re always just trying to make it better, but now that's what gets me to this really interesting question because you are a senior principal researcher at Microsoft and Microsoft might not like some of these things that you're advocating, how does that potential conflict work out?
Kate Crawford (22:23):
It's interesting. I mean, people often ask me, am I a technology optimist or a technology pessimist? And I always say I'm a technology realist, and we're looking at these systems being used. I think we are not benefited by discourses of AI doomerism nor by AI boosterism. We have to assess the real politic and the political economies into which these systems flow. So obviously part of the way that I've got to know what I know about how systems are designed and how they work at scale is through being at Microsoft Research where I'm working alongside extraordinary colleagues and all of whom come from, in many cases, professorial backgrounds who are deep experts in their fields. And we have this opportunity to work together and to look at these questions very early on in the kinds of production cycles and enormous shifts in the way that we use technology.
(23:20):
But it is interesting of course that at the moment Microsoft is absolutely at the leading edge of this change, and I've always thought that it's incredibly important for researchers and academics who are in industrial spaces to be able to speak freely, to be able to share what they see and to use that as a way that the industry can, well hopefully keep itself honest, but also share between what it knows and what everybody else knows because there's a giant risk in having those spaces be heavily demarcated and having researchers really be muzzled. I think that's where we see real problems emerge. Of course, one of the great concerns a couple of years ago was when Timnit Gebru and others were fired from Google for speaking openly about the concerns they had about the first-generation large language models. And my hope is that there's been a lesson through that really unfortunate set of decisions made at Google that we need people speaking from the inside about these questions in order to actually make these systems better, as you say, over the medium and long term.
Eric Topol (24:26):
Yeah, no, that brings me to thought of Peter Lee, who I'm sure because he wrote a book about GPT-4 and healthcare and was very candid about its potential, real benefits and the liabilities, and he's a very humble kind of guy. He's not one that has any bravado that I know of, so it speaks well to at least another colleague of yours there at Microsoft and their ability to see all the different sides here, not just what we'll talk about in a minute the arms race both across companies and countries. But before I get to that, there's this other part of you and I wonder if there's really two or three of you that is as a composer of music and art, I looked at your Anatomy of an AI System, I guess, which is on exhibit at the Museum of Modern Art (MoMA) in New York, and that in itself is amazing, but how do you get into all these other parts, are these hobbies or is this part of a main part of your creative work or where does it fit in?
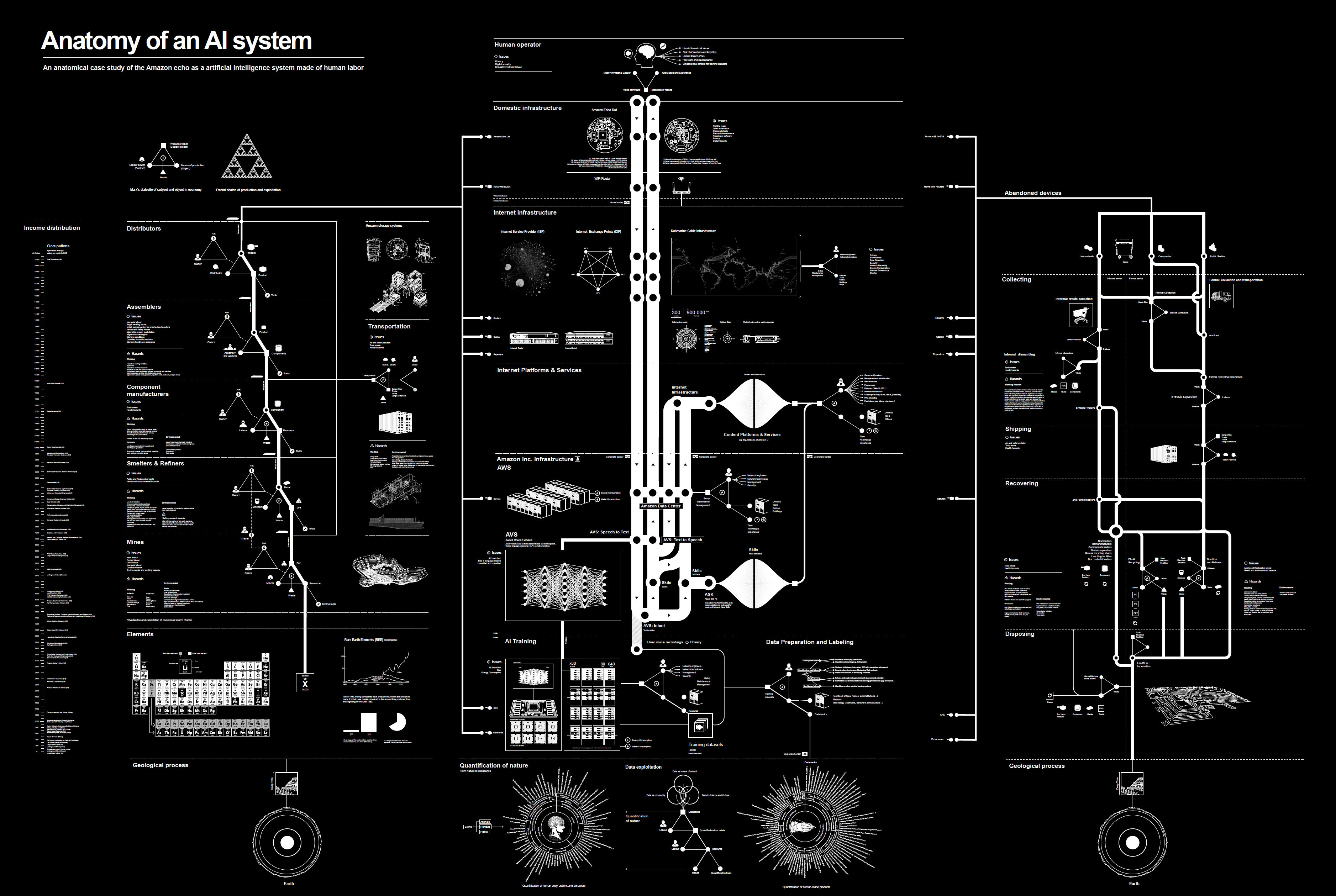
Kate Crawford (25:40):
Eric, didn't I mention the cloning program that I participated in early and that there are many Kate’s and it's fantastic we all work together. Yeah, that explains it. Look, it's interesting. Way back as a teenager, I was fascinated with technology. Of course, it was the early stages of the web at that moment, and I could see clearly that this was, the internet was going to completely change everything from my generation in terms of what we would do in terms of the way that we would experience the world. And as I was also at that time an electronic musician in bands, I was like, this was a really fantastic combination of bringing together creative practice with a set of much larger concerns and interests around at a systems level, how technology and society are co-constituted, how they evolve together and shape each other. And that’s really been the map of how I’ve always worked across my life.
(26:48):
And it’s interesting, I've always collaborated with artists and Vladan Joler who I worked with on anatomy of an AI system. We actually met at a conference on voice enabled AI systems, and it was really looking at the ethics of could it be possible to build an open source, publicly accessible version of say Alexa rather than purely a private model owned by a corporation, and could that be done in a more public open source way? And we asked a different question, we looked at each other and we're like, oh, I haven't met you yet, but I can see that there are some problems here. One of them is it's not just about the data and it's not just about the technical pipelines, it's about where the components come from. It's about the mining structures that needed to make all of these systems. It's about the entire end of life what happens when we throw these devices out from generally between three to four years of use and how they go into these giant e-waste tips.
(27:51):
And we basically started looking at this as an enormous sort of life and death of a single AI system, which for us started out by drawing these things on large pieces of butcher's paper, which just expanded and expanded until we had this enormous systems level analysis of what it takes just to ask Alexa what the weather is today. And in doing that, it taught me a couple of things. One that people really want to understand all of the things that go into making an AI system work. This piece has had a very long life. It's been in over a hundred museums around the world. It's traveled further than I have, but it's also very much about that broader political economy that AI systems aren't neutral, they don't just exist to serve us. They are often sort of fed into corporate structures that are using them to generate profits, and that means that they're used in very particular ways and that there are these externalities in terms of how they produced that linger in our environments that have really quite detrimental impacts on systems of labor and how people are recompensed and a whole range of relationships to how data is seen and used as though it's a natural resource that doesn't actually come from people's lives, that doesn't come with risks attached to it.
(29:13):
So that project was really quite profound for me. So we've continued to do these kinds of, I would call them research art projects, and we just released a new one called Calculating Empires, which looks at a 500 year history of technology and power looking specifically at how empires over time have used new technologies to centralize their power and expand and grow, which of course is part of what we're seeing at the moment in the empires of AI.
Eric Topol (29:43):
And what about the music side?
Kate Crawford (29:45):
Well, I have to say I've been a little bit slack on the music side. Things have been busy in AI Eric, I have to say it's kept me away from the music studio, but I always intend to get back there. Fortunately, I have a kid who's very musical and he's always luring me away from my desk and my research saying, let’s write some music. And so, he'll keep me honest.
Geopolitics and the Arms Races
Eric Topol (30:06):
Well, I think it's striking just because you have this blend of the humanities and you're so deep into trying to understand and improve our approaches in technology. And it seems like a very unusual, I don't know, too many techies that have these different dimensions, so that's impressive. Now let's get back to the arms race. You just were talking about tracing history over hundreds of years and empires, but right now we have a little problem. We have the big tech titans that are going after each other on a daily basis, and of course you know the group very well. And then you have China and the US that are vying to be the dominant force and problems with China accessing NVIDIA chips and Taiwan sitting there in a potentially very dangerous position, not just for Taiwan, but also for the US. And I wonder if you could just give us your sense about the tensions here. They're US based as well of course, because that's some of the major forces in companies, but then they're also globally. So we have a lot of stuff in the background that people don't like to think about, but it's actually happening right now.
Kate Crawford (31:35):
I think it's one of the most important things that we can focus on, in fact. I mean and again, this is why I think a materialist analysis of artificial intelligence is so important because not only does it force you to look at the raw components, where does the energy come from? Where does the water come from? But it means you're looking at where the chipsets come from. And you can see that in many cases there are these infrastructural choke points where we are highly dependent on specific components that sit within geopolitical flashpoints. And Taiwan is really the exemplar of this sort of choke point at the moment. And again, several companies are trying to address this by spinning up new factories to build these components, but this takes a lot of time and an enormous amount of resources yet again. So what we're seeing is I think a very difficult moment in the geopolitics of artificial intelligence.
(32:31):
What we've had certainly for the last decade has been almost a geopolitical duopoly. We've had the US and China not only having enormous power and influence in this space, but also goading each other into producing the most extreme forms of both data extractive and surveillance technologies. And unfortunately, this is just as true in the United States that I commonly hear this in rooms in DC where you'll hear advisors say, well, having any type of guardrails or ethical considerations for our AI systems is a problem if it means that China's going to do it anyway. And that creates this race to the bottom dynamic of do as much of whatever you can do regardless of the ethical and in some cases legal problems that will create. And I think that's been the dynamic that we've seen for some time. And of course the last 18 months to two years, we've seen that really extraordinary AI war happening internally in the United States where again, this race dynamic I think does create unfortunately this tendency to just go as fast as possible without thinking about potential downsides.
(33:53):
And I think we're seeing the legacy of that right now. And of course, a lot of the conversations from people designing these systems are now starting to say, look, being first is great, but we don’t want to be in a situation as we saw recently with Google’s Gemini where you have to pull an entire model off the shelves and you have to say, this is not ready. We actually have to remove it and start again. So this is the result I think of that high pressure, high speed dynamic that we’ve been seeing both inside the US but between the US and China. And of course, what that does to the rest of the world is create this kind of client states where we've got the EU trying to say, alright, well we'll export a regulatory model if we're not going to be treated as an equivalent player here. And then of course, so many other countries who are just seen as spaces to extract low paid labor or the mineralogical layer. So that is the big problem that I see is that that dynamic has only intensified in recent years.
A.I. and Medicine
Eric Topol (34:54):
Yeah, I know it's really another level of concern and it seems like it could be pretty volatile if for example, if the US China relations takes another dive and the tensions there go to levels that haven't been seen so far. I guess the other thing, there's so much that is I think controversial, unsettled in this space and so much excitement. I mean, just yesterday for example, was the first AI randomized trial to show that you could save lives. When I wrote that up, it was about the four other studies that showed how it wasn't working. Different studies of course, but there's so much excitement at the same time, there's deep concerns. You've been a master at articulating these deep concerns. What have we missed in our discussion today, I mean we've covered a lot of ground, but what do you see are other things that should be mentioned?
Kate Crawford (36:04):
Well, one of the things that I've loved in terms of following your work, Eric, is that you very carefully walk that line between allowing the excitement when we see really wonderful studies come out that say, look, there's great potential here, but also articulating concerns where you see them. So I think I'd love to hear, I mean take this opportunity to ask you a question and say what's exciting you about the way that this particularly new generation AI is being used in the medical context and what are the biggest concerns you have there?
Eric Topol (36:35):
Yeah, and it's interesting because the biggest advance so far in research and medicine was the study yesterday using deep learning without any transformer large language model effort. And that's where that multiplicative of opportunity or potential is still very iffy, it's wobbly. I mean, it needs much more refinement than where we are right now. It's exciting because it is multimodal and it brings in the ability to bring all the layers of a human being to understand our uniqueness and then do much better in terms of, I got a piece coming out soon in Science about medical forecasting and how we could really get to prevention of conditions that people are at high risk. I mean like for example today the US preventive task force said that all women age 40 should have mammograms, 40.
Kate Crawford (37:30):
I saw that.
Eric Topol (37:30):
Yeah, and this is just crazy Looney Tunes because here we have the potential to know pretty precisely who are those 12%, only 12% of women who would ever get breast cancer in their lifetime, and why should we put the other 88% through all this no less the fact that there are some women even younger than age 40 that have significantly high risk that are not picked up. But I do think eventually when we get these large language models to actualize their potential, we'll do really great forecasting and we'll be able to not just prevent or forestall cancer, Alzheimer’s and so many things. It's quite exciting, but it's the earliest, we're not even at first base yet, but I think I can see our way to get there eventually. And it's interesting because the discussion I had previously with Geoffrey Hinton, and I wonder if you think this as well, that he sees the health medical space as the only really safe space. He thinks most everything else has got more concerns about the downsides is the sweet spot as he called it. But I know that's not particularly an area that you are into, but I wonder if you share that the excitement about your health could be improved in the future with AI.
Kate Crawford (38:52):
Well, I think it's a space of enormous potential, but again, enormous risk for the same reasons that we discussed earlier, which is we have to look at the training data and where it's coming from. Do we have truly representative sources of data? And this of course has been a consistent problem certainly for the last hundred years and longer. When we look at who are the medical patients whose data is being collected, are we seeing skews? And that has created all sorts of problems, particularly in the last 50 years in terms of misdiagnosing women, people of color, missing and not taking seriously the health complaints of people who are already seen as marginalized populations, thus then further skewing the data that is then used to train AI models. So this is something that we have to take very seriously, and I had the great fortune of being invited by Francis Collins to work with the NIH on their AI advisory board.
(39:50):
They produced a board to look just at these questions around how can this moment in AI be harnessed in such a way that we can think about the data layer, think about the quality of data and how we train models. And it was a really fascinating sort of year long discussion because in the room we had people who were just technologists who just wanted as much data as possible and just give us all that data and then we'll do something, but we'll figure it out later. Then there were people who had been part of the Human Genome Project and had worked with Francis on questions around the legal and ethical and social questions, which he had really centered in that project very early on. And they said, no, we have to learn these lessons. We have to learn that data comes from somewhere. It's not divorced of context, and we have to think about who's being represented there and also who's not being represented there because that will then be intensified in any model that we train on that data.
Humans and Automation Bias
(40:48):
And then also thinking about what would happen in terms of if those models are only held by a few companies who can profit from them and not more publicly and widely shared. These were the sorts of conversations that I think at the absolute forefront in terms of how we're going to navigate this moment. But if we get that right, if we center those questions, then I think we have far greater potential here than we might imagine. But I'm also really cognizant of the fact that even if you have a perfect AI model, you are always going to have imperfect people applying it. And I'm sure you saw that same study that came out in JAMA back in December last year, which was looking at how AI bias, even slightly biased models can worsen human medical diagnosis. I don’t know if you saw this study, but I thought it was really extraordinary.
(41:38):
It was sort of 450 doctors and physician's assistants and they were really being shown a handful of cases of patients with acute respiratory failure and they really needed come up with some sort of diagnosis and they were getting suggestions from an AI model. One model was trained very carefully with highly accurate data, and the other was a fairly shoddy, shall we say, AI model with quite biased data. And what was interesting is that the clinicians when they were working with very well-trained AI model, we're actually producing a better diagnosis across the board in terms of the cases they were looking at. I think their accuracy went up by almost 4.5 percentage points, but when they were working with the less accurate model, their capacity actually dropped well below their usual diagnostic baseline, something like almost 12 percentage points below their usual diagnostic quality. And so, this really makes me think of the kind of core problem that's been really studied for 40 years by social scientists, which is called automation bias, which is when even an expert, a technical system which is giving a recommendation, our tendency is to believe it and to discard our own knowledge, our own predictions, our own sense.
(42:58):
And it's been tested with fighter pilots, it's been tested with doctors, it's been tested with judges, and it's the same phenomenon across the board. So one of the things that we're going to need to do collectively, but particularly in the space of medicine and healthcare, is retaining that skepticism, retaining that ability to ask questions of where did this recommendation come from with this AI system and should I trust it? What was it trained on? Where did the data come from? What might those gaps be? Because we're going to need that skepticism if we're going to get through particularly this, as you say, this sort of early stage one period where in many cases these models just haven't had a lot of testing yet and people are going to tend to believe them out of the box.
The Large Language Model Copyright Issue
Eric Topol (43:45):
No, it's so true. And one of the key points is that almost every study that's been published in large language models in medicine are contrived. They're using patient actors or they're using case studies, but they're not in the real world. And that's where you have to really learn, as you know, that's a much more complex and messy world than the in silico world of course. Now, before wrapping up, one of the things that's controversial we didn't yet hit is the fact that in order for these base models to get trained, they basically ingest all human content. So they've ingested everything you've ever written, your books, your articles, my books, my articles, and you have the likes of the New York Times suing OpenAI, and soon it's going to run out of human content and just use synthetic content, I guess. But what's your sense about this? Do you feel that that's trespassing or is this another example of exploiting content and people, or is this really what has to be done in order to really make all this work?
Kate Crawford (44:59):
Well, isn't it a fascinating moment to see this mass grabbing of data, everything that is possibly extractable. I actually just recently published an article in Grey Room with the legal scholar, Jason Schultz, looking at how this is producing a crisis in copyright law because in many ways, copyright law just cannot contend with generative AI in particular because all of the ways in which copyright law and intellectual property more broadly has been understood, has been premised around human ideas of providing an incentive and thus a limited time monopoly based on really inspiring people to create more things. Well, this doesn't apply to algorithms, they don't respond to incentives in this way. The fact that, again, it's a longstanding tradition in copyright that we do not give copyright to non-human authors. So you might remember that there was a very famous monkey selfie case where a monkey had actually stepped on a camera and it had triggered a photograph of the monkey, and could this actually be a copyright image that could be given to the monkey?
(46:12):
Absolutely not, is what the court's decided. And the same has now happened, of course, for all generative AI systems. So right now, everything that you produce be that in GPT or in Midjourney or in Stable Diffusion, you name it, that does not have copyright protections. So we're in the biggest experiment of production after copyright in world history, and I don't think it's going to last very long. To be clear, I think we're going to start to see some real shifts, I think really in the next 6 to 12 months. But it has been this moment of seeing this gigantic gap in what our legal structures can do that they just haven't been able to contend with this moment. The same thing is true, I think, of ingestion, of this capturing of human content without consent. Clearly, many artists, many writers, many publishing houses like the New York Times are very concerned about this, but the difficulty that they're presented with is this idea of fair use, that you can collect large amounts of data if you are doing something with that, which is sufficiently transformative.
(47:17):
I'm really interested in the question of whether or not this does constitute sufficiently transformative uses. Certainly if you looked at the way that large language models a year ago, you could really prompt them into sharing their training data, spitting out entire New York Times articles or entire book chapters. That is no longer the case. All of the major companies building these systems have really safeguarded against that now but nonetheless, you have this question of should we be moving towards a system that is based on licensing, where we're really asking people if we can use their data and paying them a license fee? You can see how that could absolutely work and would address a lot of these concerns, but ultimately it will rely on this question of fair use. And I think with the current legal structures that we have in the current case law, that is unlikely to be seen as something that's actionable.
(48:10):
But I expect what we'll look at is what really happened in the early 20th century around the player piano, which was that I'm sure you remember this extraordinary technology of the player piano. That was one of the first systems that automated the playing of music and you'd have a piano that had a wax cylinder that almost like code had imprinted on a song or a piece of music, and it could be played in the public square or in a bar or in a saloon without having to pay a single artist and artists were terrified. They were furious, they were public hearings, there were sort of congressional hearings and even a Supreme Court case that decided that this was not a copyright infringement. This was a sufficiently transformative use of a piece of music that it could stand. And in the end, it was actually Congress that acted.
(49:01):
And we from that got the 1908 Copyright Act and from that we got this idea of royalties. And that has become the basis of the music industry itself for a very long time. And now we're facing another moment where I think we have a legislative challenge. How would you actually create a different paradigm for AI that would recognize a new licensing system that would reward artists, writers, musicians, all of the people whose work has been ingested into training data for AI so that they are recognized and in some ways, recompensed by this massive at scale extraction?
Eric Topol (49:48):
Wow, this has been an exhilarating conversation, Kate. I've learned so much from you over the years, but especially even just our chance to talk today. You articulate these problems so well, and I know you're working on solutions to almost everything, and you're so young, you could probably make a difference in the decades ahead. This is great, so I want to thank you not just for the chance to visit today, but all the work that you've been doing, you and your colleagues to make AI better, make it fulfill the great promise that it has. It is so extraordinary, and hopefully it'll deliver on some of the things that we have big unmet needs, so thanks to you. This has really been fun.
Kate Crawford (50:35):
This has been wonderful. And likewise, Eric, your work has just been a fantastic influence and I've been delighted to get to know you over the years and let's see what happens. It's going to be a wild ride from now to who knows when.
Eric Topol (50:48):
No question, but you'll keep us straight, I know that. Thank you so much.
Kate Crawford (50:52):
Thanks so much, Eric.
*******************************
Your support of subscribing to Ground Truths, and sharing it with your network of friends and colleagues, is much appreciated.
The Ground Truths newsletters and podcasts are all free, open-access, without ads.
Voluntary paid subscriptions all go to support Scripps Research. Many thanks for that—they greatly helped fund our summer internship programs for 2023 and 2024.
Thanks to my producer Jessica Nguyen and Sinjun Balabanoff tor audio and video support at Scripps Research
Note: you can select preferences to receive emails about newsletters, podcasts, or all I don’t want to bother you with an email for content that you’re not interested in.
Comments for this post are welcome from all subscribers.









Share this post